
华为ICT大赛昇腾AI赛道学习笔记(1)——深度学习
本文章旨在总结华为ICT大赛昇腾AI赛道培训课有关深度学习的知识点
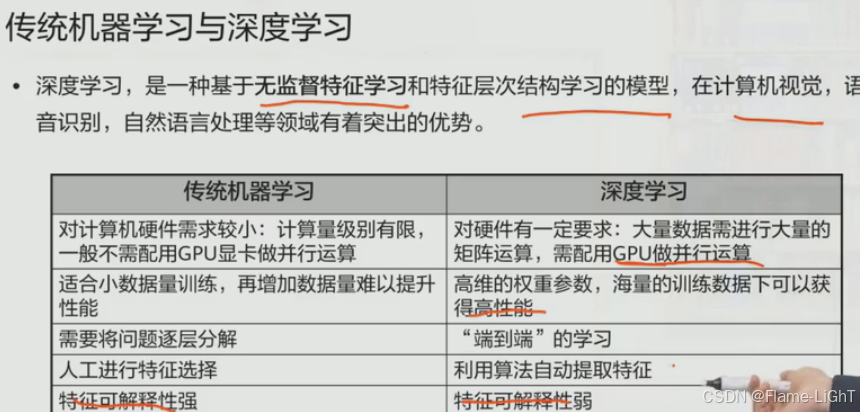
简介
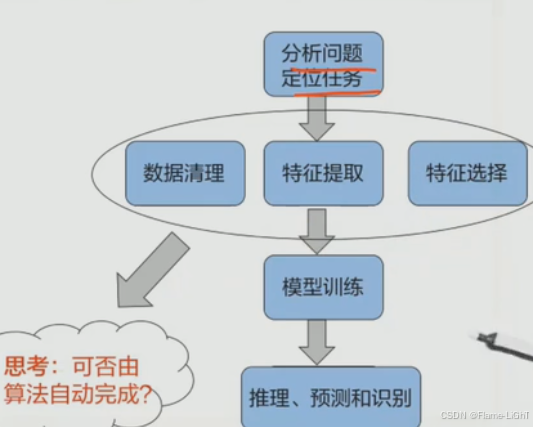
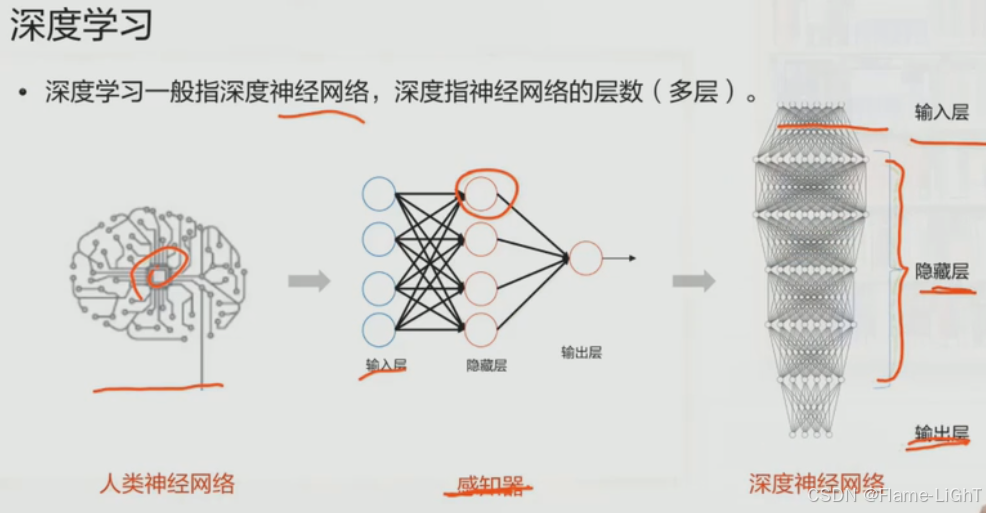
特征提取,特征选择就是在隐藏层完成的
层次越深特征越抽象,人越难理解
感知器

单层感知器实际上式实现了一个二分类的任务
B可以通过增广矩阵加入到X和W中
XOR问题
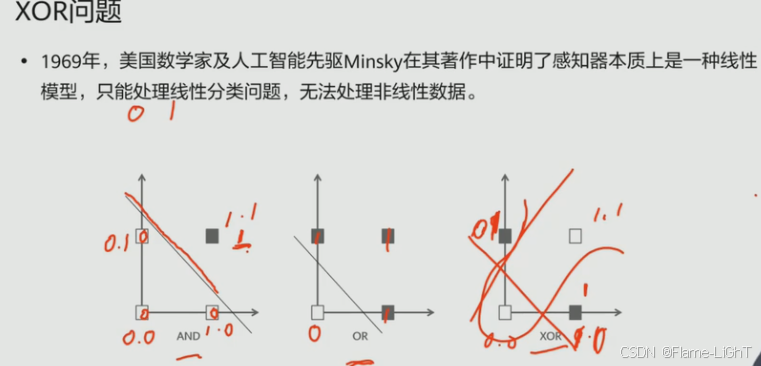
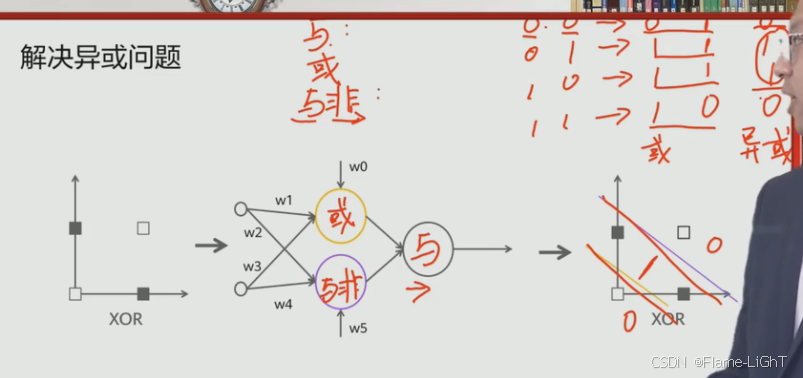
使用多层感知机来解决非线性问题
训练法则
损失函数

最小化


找到模型参数的最优值,从而提高模型的预测准确度
BGD

SGD

MBGD

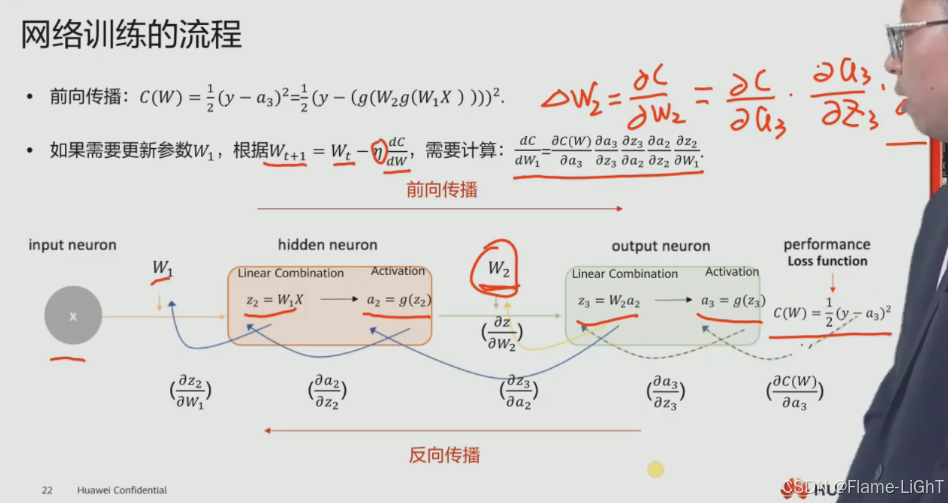
网络训练的流程
前向传播和反向传播

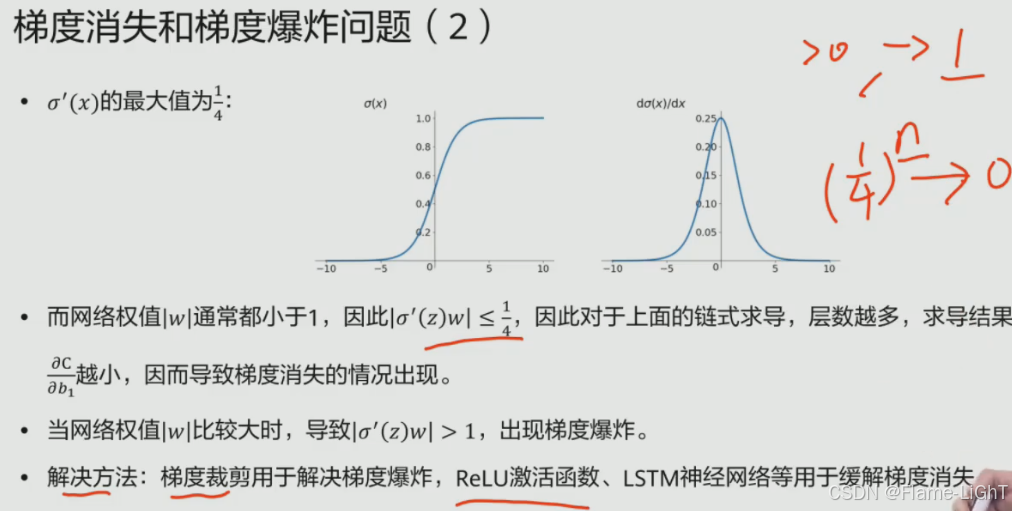
梯度消失和梯度爆炸

根本原因是梯度函数的导数值问题
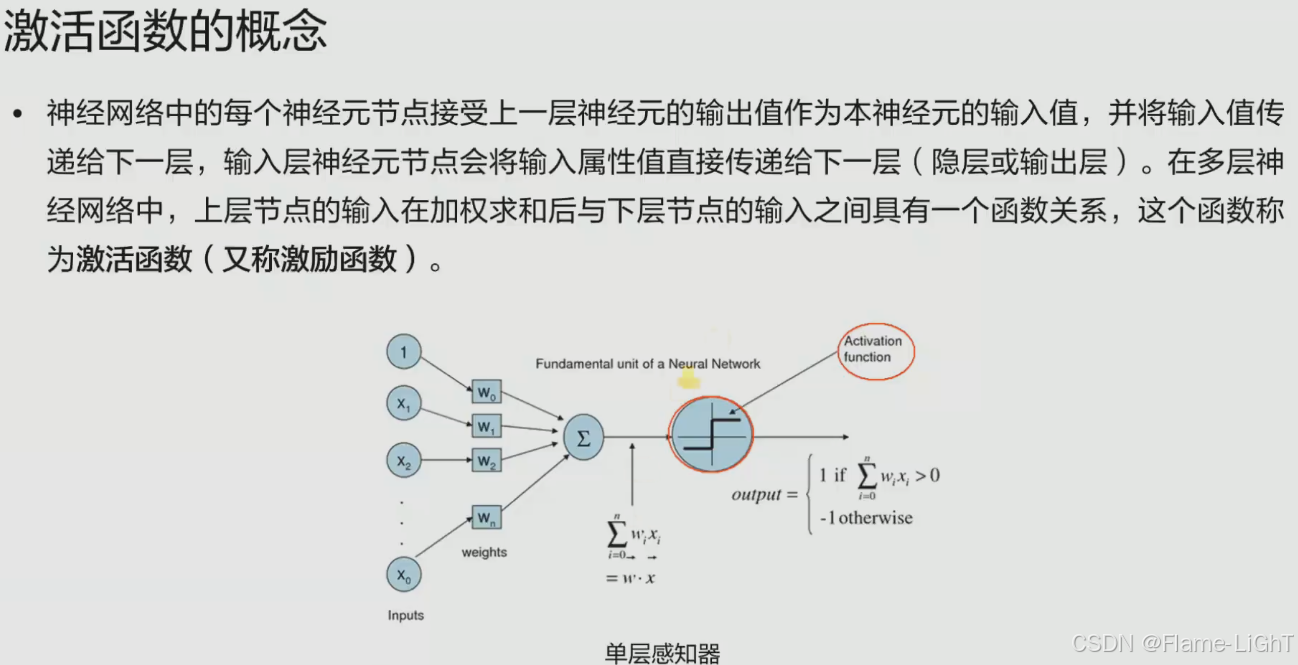
激活函数
使神经网络产生解决非线性问题的部件
每一层的输入乘以权重就会形成下一层的输出,输出通过一个非线性的函数(激活函数)
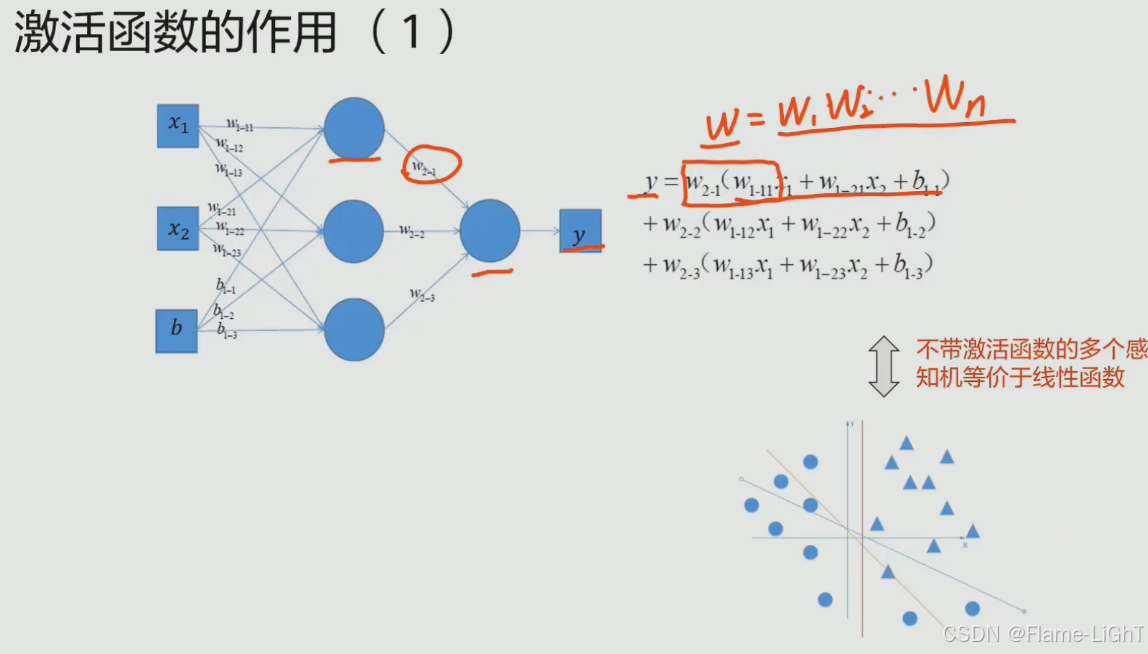
无论神经网络有多少层,最后都可以用一个值代替前面的所有的权重值,整个神经网络表达一个y=kx+b的线性关系,最终用两层神经网络来代替
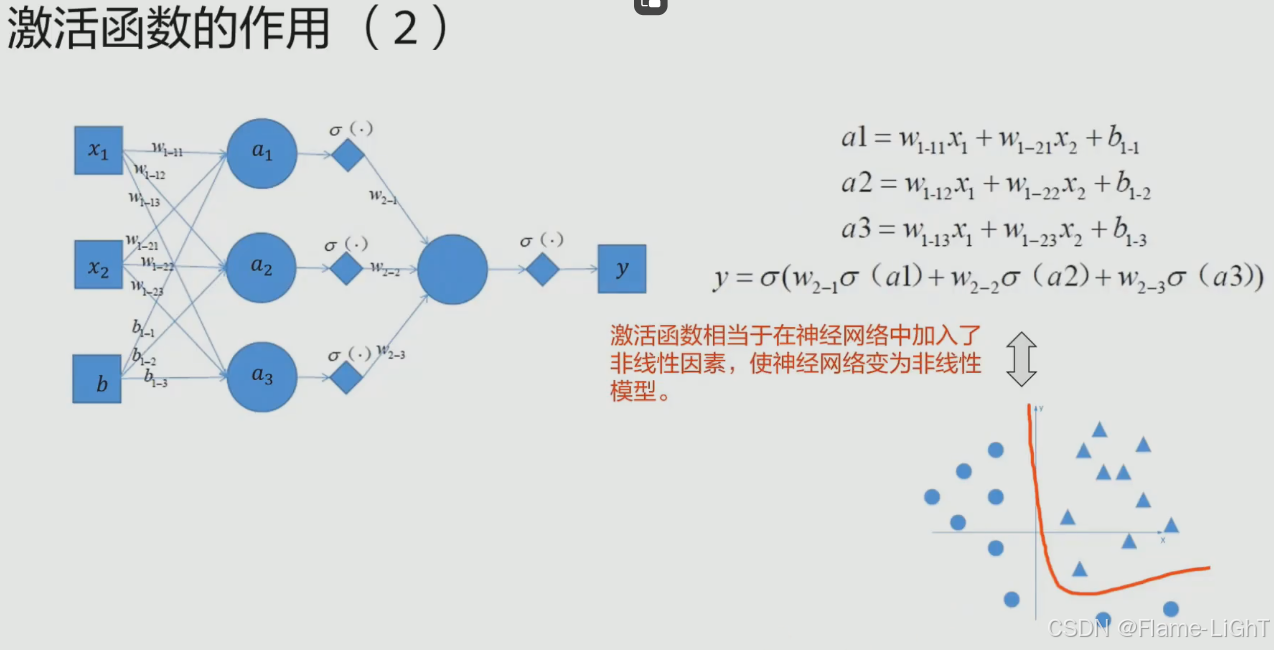
不引入激活函数无法解决非线性问题
sigmoid函数
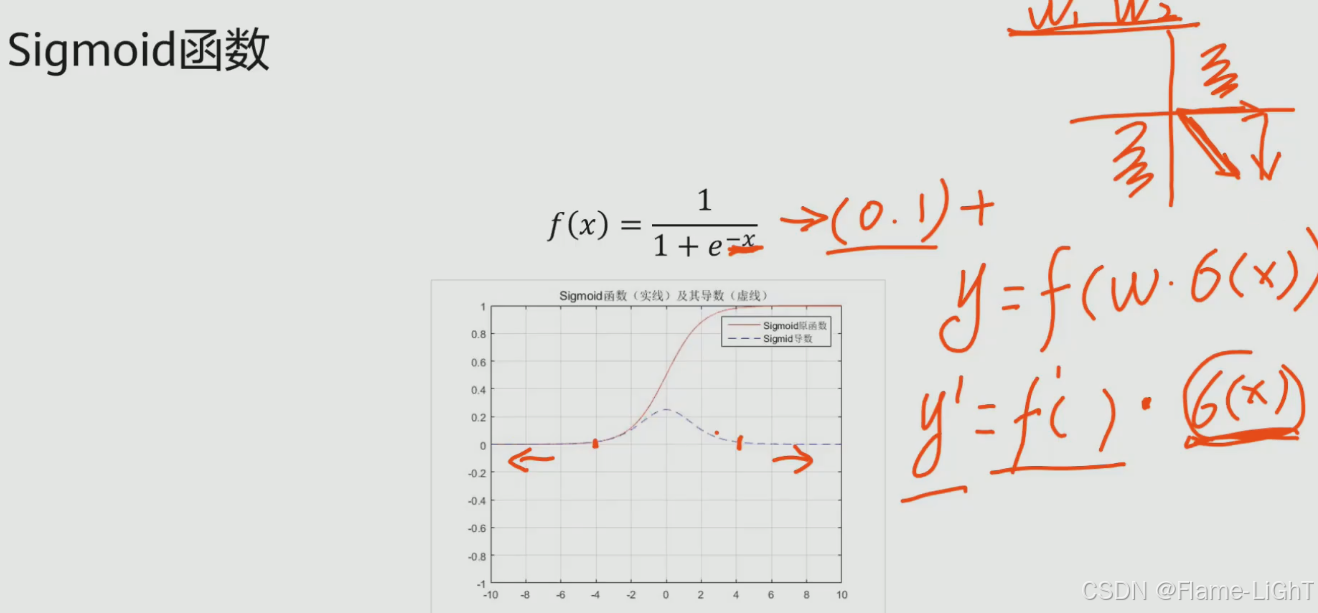
激活函数要求连续可导
虚线是sigmoid的导数曲线
层数增加的时候会出现梯度消失问题,导数趋近0
值域 (0,1),在输入一个值会转化成(0,1)的值会影响训练速度:无法直接在象限内进行梯度下降,必须沿着轴来走
改进方法:
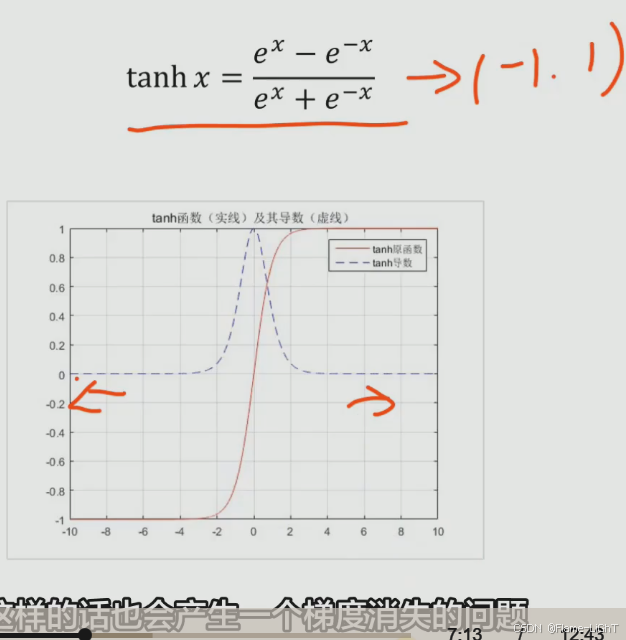
tanh函数
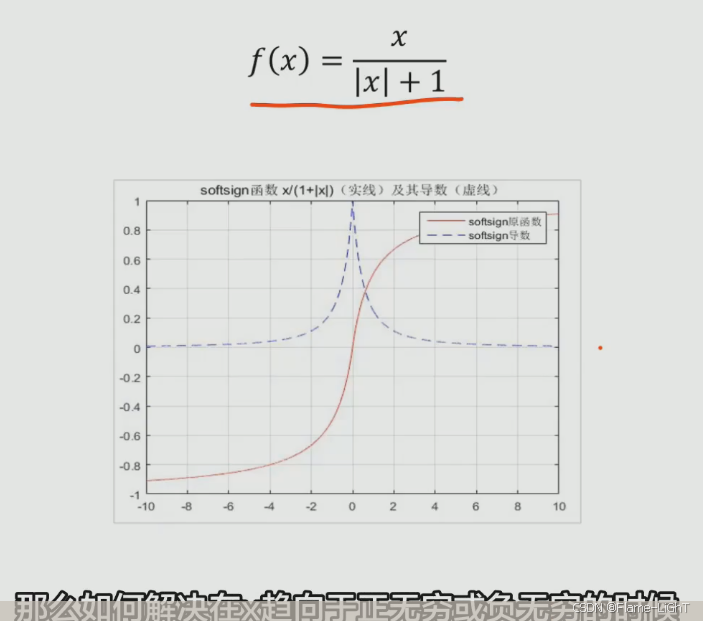
softsign函数
ReLU函数 (Rectified Linear Unit)
deadReLU现象:
如果x小于0relu函数取0,那么f的导数1乘以relu函数的一个数值也为0,这个神经元中的参数很可能不更新
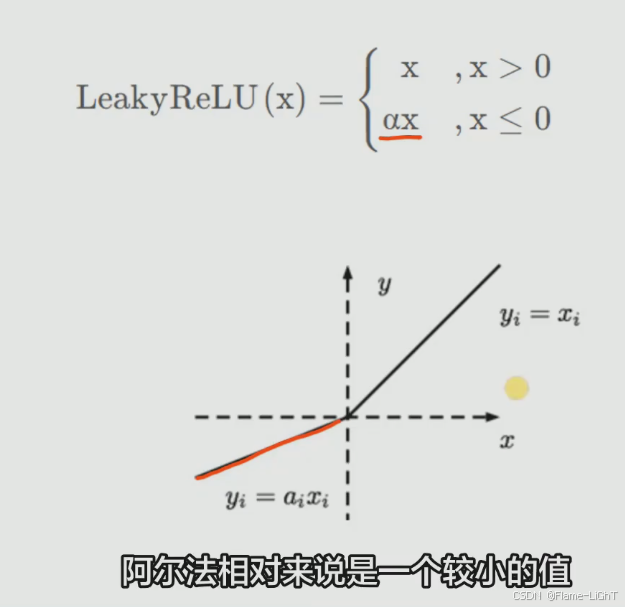
LeakyReLU函数
解决deadrelu,只要α不等于1,就能保持线性特性
SoftPlus函数
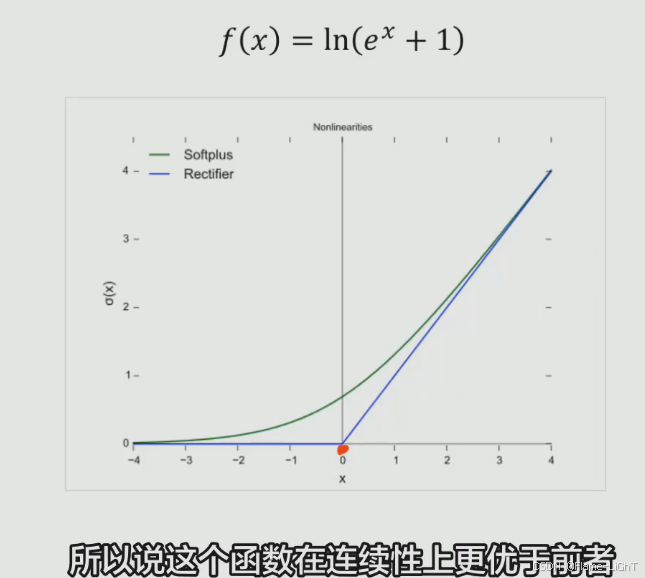
实际很少用,因为在反向传播的过程求导的过程中ln和指数函数运算量非常大
SoftMax函数

值域(0,1)
分子所有项加起来=分母,该层神经元如果求和最后输出总和为1(100%)所以经常用作多酚类任务
总结
实际常用ReLU或者LeakyReLU
正则化
用于解决过拟合问题

参数量(特征量)远大于数据本身量

后两者是用来约束训练过程
参数惩罚

L1正则

目标函数(红色圆圈)与参数约束范围(绿色正方形)相交的时候是最优参数取值
L1正则使得参数产生很多的0,某一些w为0的话有一些特征失活了,L1形成了一个特征选择的过程降低特征维数达到目的
L2正则(常用)


数据增强
增加数据量

提前停止训练
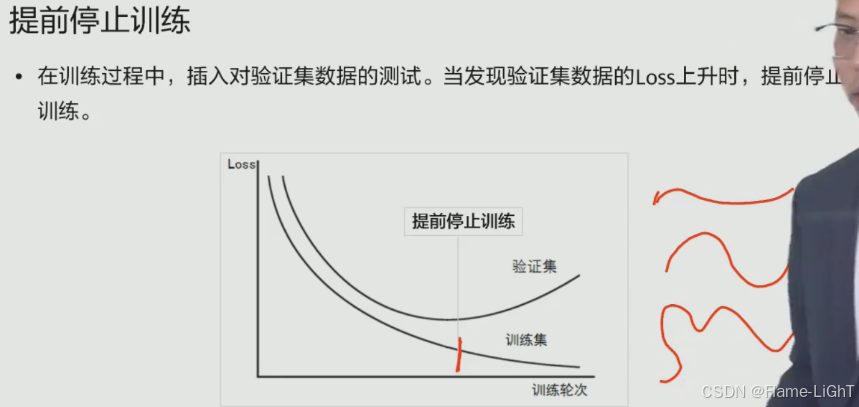
将训练集切出一部分作为验证集
训练过程中损失函数(LOSS)下降但是验证过程中LOSS函数升高时可以停止了
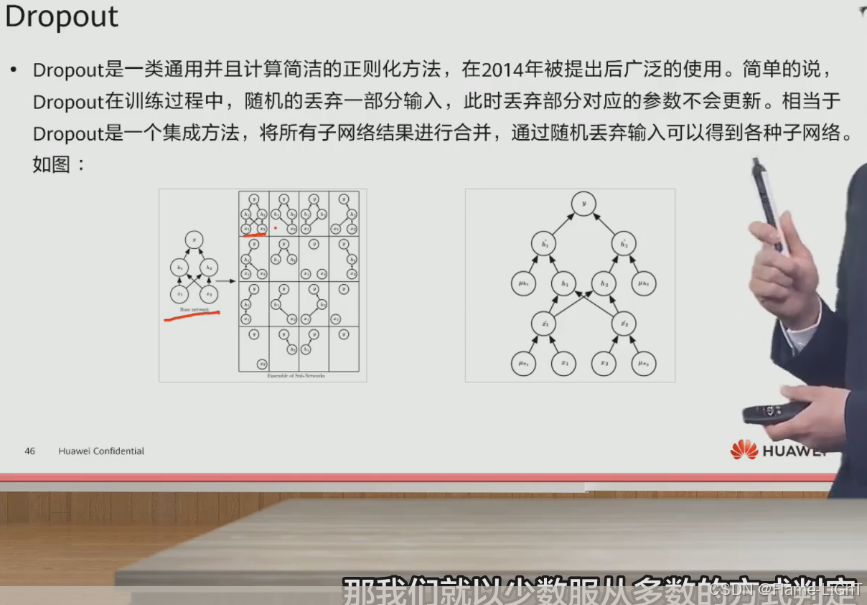
DropOut(随机失活)
每次将模型中的一些节点抛弃掉,抛弃掉的节点不同就会形成不同的神经网络,可以理解为求平均的方式
注:抛弃掉不意味这部分神经元不参与训练了,而是丢弃部分的参数不更新了,下次训练可能会重新激活
影响模型泛化能力的因素
数据不平衡问题

解决:

如果有超过2000个类别中只有一张图片不能用随机欠采样,因为不可能把2000缩减到1张此时应该使用下两个方法
优化器
加快训练过程的梯度下降算法

gt:梯度,损失函数(一个高维函数)求其某一点梯度时(对每一个变量进行求偏导)梯度就是偏导的集合
每次随机抽取数据进行训练得到的梯度大小和方向都不一样,优化器就是使梯度方向更快的路径趋向最大最小值,加快算法收敛速度
η:学习率(一个超参数),每次优化的步幅长度,不乘的话可能会跳过某个局部的最小值点,每次优化要逐步减少
动量优化器
优化梯度


需要手动选择η和α
Adagrad优化器
优化学习率

梯度平方的累加
伊普西隆是防止一开始根号r=0时整个分母都为0

RMSprop优化器
解决过早结束问题优化学习率

Adam优化器
结合了前面的优势:梯度,学习率优化

不直接用g1而是除以一个1-β²1 正好约掉前面的1-β1
更新方式:w(t+1)等于wt减去我们设置的全局学习率除以我们的分母再乘以一个梯度的一个优化

神经网络
一个神经元都与前一层所有的神经元进行相连,每一个连接上都会有一个权重参数。这样的话我们整个全连接神经网络的参数是非常多的当我们有视频中的相邻两帧输入到全连接神经网络里的话,前一帧物体在某一个位置,那么后一针这个物体的位置可能就发生了变化。对于全连接神经网络来说的话,这个变化它是比较敏感的。
在图像识别领域有优势:通过卷积核遍历图像
卷积神经网络(Convolutional Neural Network,CNN)

卷积神经网络核心思想

相邻像素值之间的一个联系是比较紧密的。较远的像素值它们之间的关联性比较弱的,所以局部的神经元没有必要对图像的全部信息进行感知,它只需要感知部分局部的特征就可以了
卷积神经网络架构
卷积神经网络就是通过不断的卷积池化卷积池化得到一系列的一个特征图。在后面的部分将这些特征图直接拉伸成一个全链接图,然后投入到我们的一个输入层进行一个判断,最后得出结果
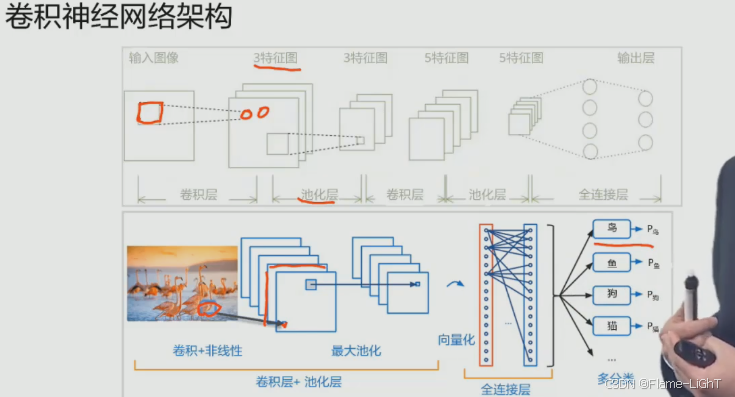
卷积核在这里会提取鸟的部分特征,然后保存在后一层使用当这个卷积核扫描完整张图片之后,它就会形成一个特征图。如果这个卷积核只提取了部分特征,我们在使用另外一个卷积核来扫描的图片进行自动提取,就会在后面形成第二个特征图,以此类推,我们使用多个卷积盒的话,就会形成多张特征图拉伸得到一个向量化的结构,进行一个全链接层的链接。最后通过全链接层输出,我们对本张图的一个预测。
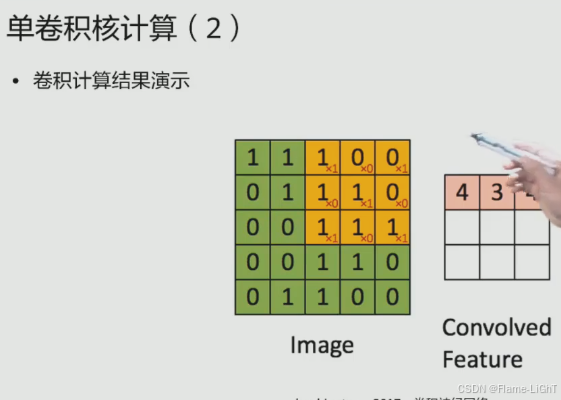
单卷积核计算
卷积核的作用主要就是用来特征提取

首先卷积核会在图像中的左上角画红框部分,也就是说左上角与图像重合。然后卷积核中每一个数值与图像中对应的数值进行相乘,然后再求和求得这样的一个值。我们会将这个输出存到下一层中(橙色部分的一个小红圆圈)
神经元与整个图像中这一部分人员进行了一个连接。这也就是我们前面提到的局部感知卷积核会在图像中不停的移动,直到遍历完我们整张图像。卷积核每走一步,就将我们得到的数值保存到下一层神经元中。当我们的卷积核建立完成之后,就形成了一个下一层的一个特征图
设原始图像大小P,卷积核大小F,特征图大小M,将它每次移动的一个距离称为步长S
一个3乘3的卷积核,我们当它放到一个5*5的图像中,它首先覆盖掉了一个3乘3的这个区域。这时候我们用我们的P减去我们整个核的一个尺寸,它在x方向上可以3次,同理y方向也移动三次,然后朝x方向移动三次直到到达边缘
除以步长,再加上1,就得到了我们一个特征图的大小
想要不同大小的一个输出特征 在原始图像周围补充一圈新的像素值,这样的话我们就改变了我们的P从而改变我们各种图M的大小 称为填充。
设填充值为T,乘上2T 不改变我们输入的值大小。使用多个一乘一的卷积核,就可以得到与原图带有同样相同的一个特征图
要提取多方面的特征,我们就可以使用多个卷积核来训练不同参数
注:如果除以步长之后产生小数(x.5)向下取整,因为不可能有小数的
移动一次,就算是一个数值保存到下一层的一个特征符里面。在这里的话,我们看到黄色区域里面右下角这个红色数字,就是我们卷积核的隐藏参数。它的遍历整个图像的过程中,这个参数是保持统一的 一个卷积核在提取整个装修中的时候参数不发生变化,也就实现了我们的参数共享,从而大大减少了参数数量,实现一类卷积核只提取一种特征的功能
卷积层
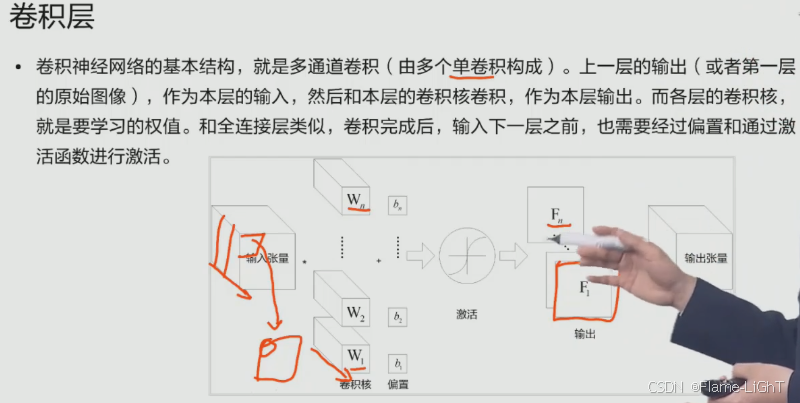
在这个方向上是有一个维度的 如果说这里我们有三个维度 必须使用与输入同样一步的一个等级核。也就是说我们从单一的一核变成了多点一核。这里的话就是我们这个维度上面与我们输入的维度是相同的。第一个卷积核与输入进行卷积多通道的一个卷积核卷积 会计算得到一个值,那么每个通道都会得到一个值。最后我们会将这个值进行相加,得到一个值。同样得到了之后我们会得到下一层一个神经元,多个卷积核合成数据的到新的特征图也需要加上一个添置,然后再经过激活函数得到我们第一个特征图
多个卷积核n个通道进行卷积
池化层
防止数据偏移的不变性,降低神经网络里面的参数
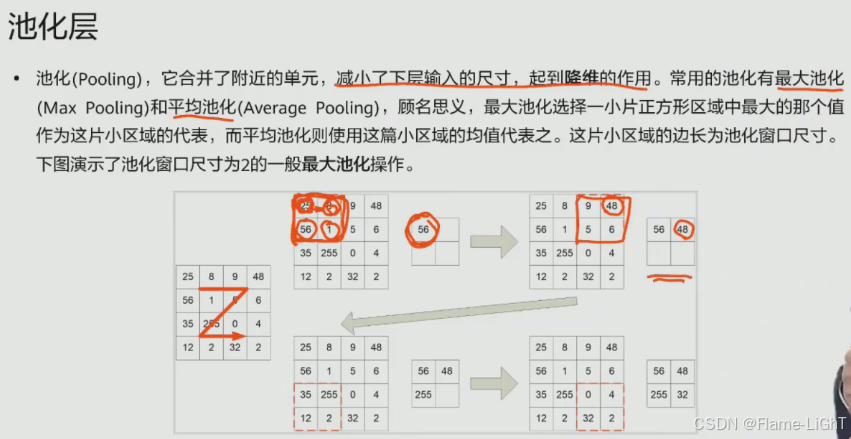
最大池化和平均池化
全连接层
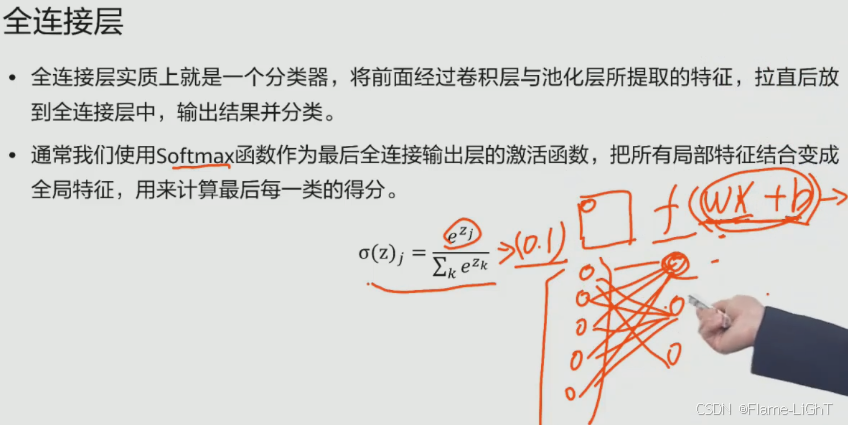
将特征图里的特征拉直放到一个向量中
假设有三个分类,前一层的神经元会与后面分类的每一个神经元连接(全连接)让提取的特征参与到分类中
权重乘以特征加上偏置
循环神经网络(Recurrent neural networks,RNN)
主要处理时序上的问题

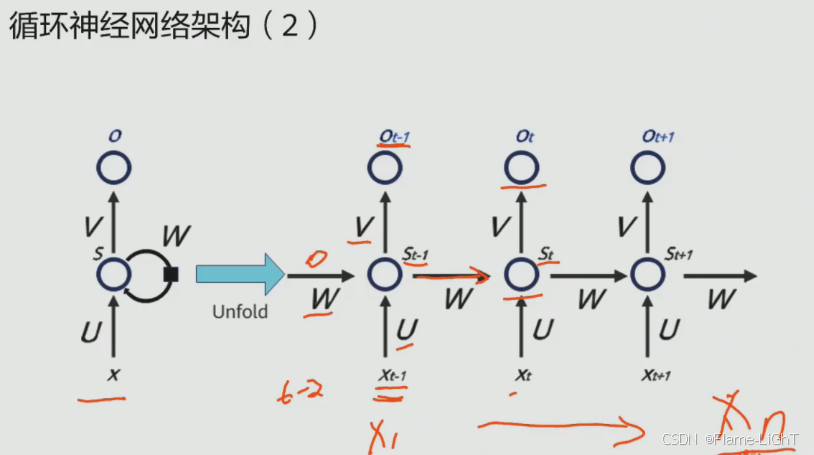
循环神经网络架构

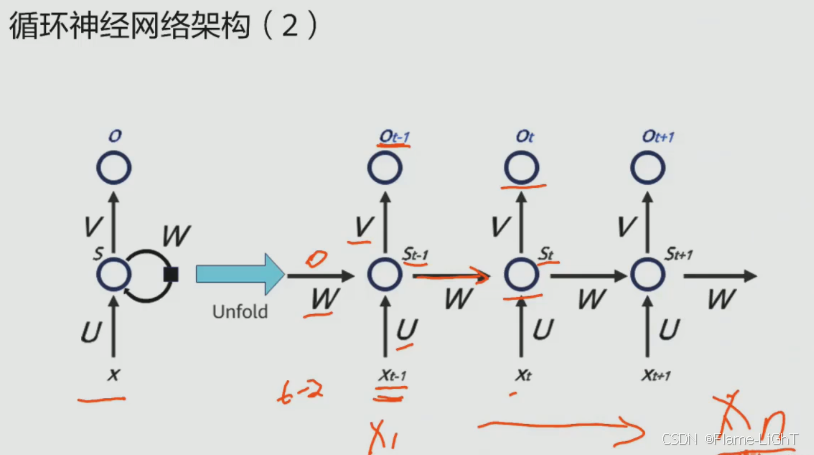
并不像卷积神经网络那样直接输出,而是循环一遍再加上t-1时刻的数据再输出
循环神经网络类型
判断图片类别 一对一
描述图片的文本 一对多
一句话进行情感类型 多对一
机器翻译,一句画中很多个词 多对多
按顺序标注序列
时序反向传播(BPTT)

循环神经网络问题

长短记忆性网络(LSTM)
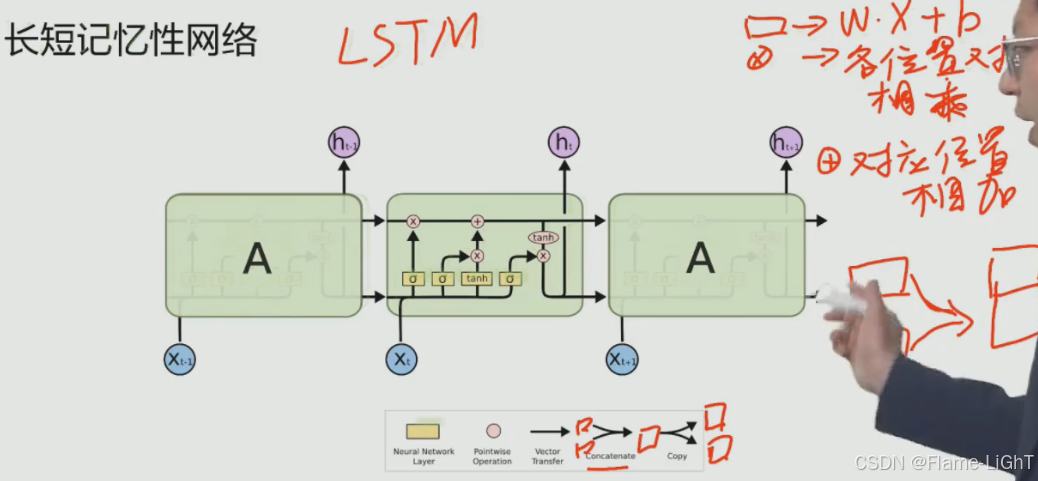
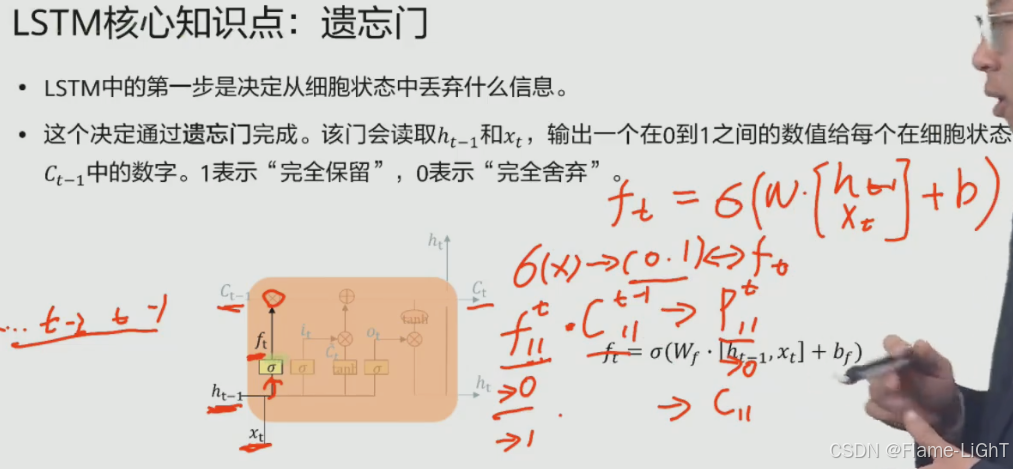
遗忘门
C:cell,存储前面时刻有价值的信息
遗忘就是结合当前已知的信息判断哪些保留哪些丢弃
输入门
连接是将两个数据拼接起来
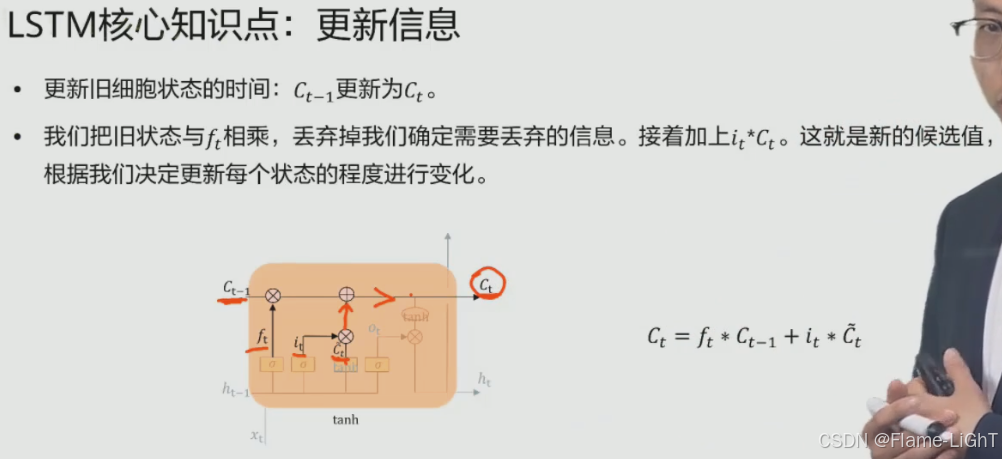
使用ft更新旧的信息Ct-1,然后将t时刻更新之后的旧的信息与t时刻选择要保留的信息相加,等于往后传播的信息Ct
更新之后并没有输出,所以需要:
输出门
Ot和前面的ft it都是选择性作用
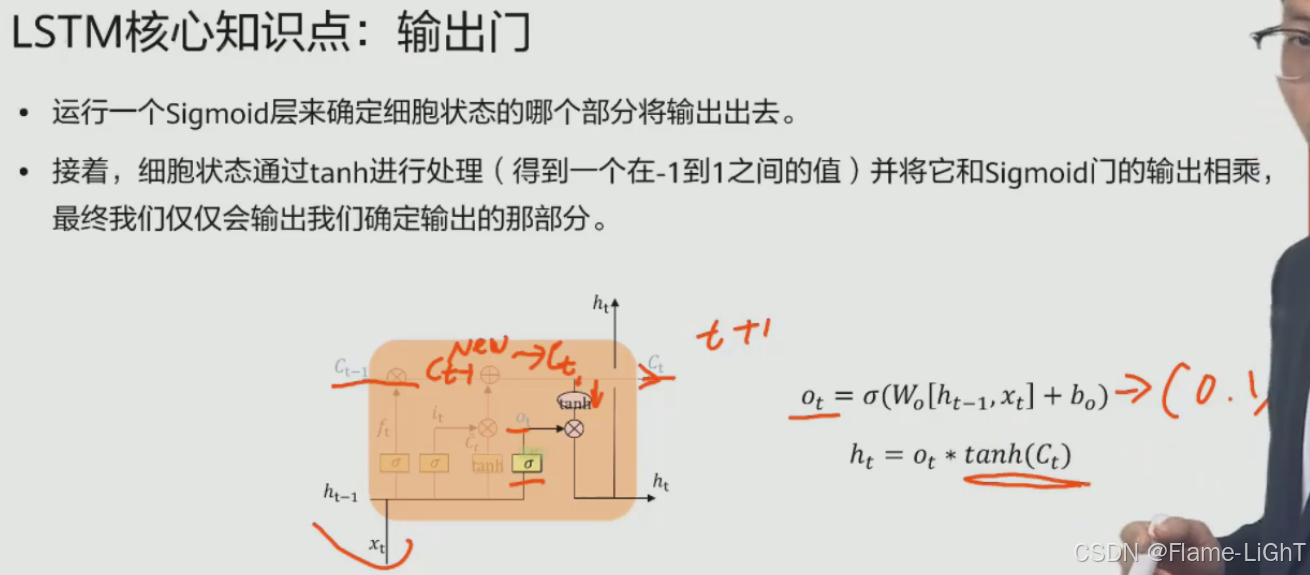
筛选两次:前面遗传的信息筛选,本次的输入筛选

科技之力与好奇之心,共建有温度的智能世界
更多推荐



 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)