
2025最新导入和部署 Stable Diffusion ComfyUI 服务
本节为您介绍,如何基于平台基础镜像构建自定义镜像,并上传到自定义镜像仓库,进行部署服务使用。\1. 以下用自定义镜像 ccr.ccs.tencentyun.com/test/stable-diffusion-webui:comfyui-1.0.1,举例说明:自定义镜像 Dockerfile。##### ----- 【您按需进行替换: Begin】 ---------##### -----
总览
ComfyUI 是一个为 Stable Diffusion 专门设计的基于节点的图形用户界面(GUI)。它使用户能够通过链接不同的块(称为节点)来构建复杂的图像生成工作流程。与 SD-WebUI 相比,ComfyUI 提供了极高的自由度和灵活性,支持高度的定制化和工作流复用。
本文为您介绍如何基于平台基础镜像,构建 ComfyUI 自定义镜像,并导入SD模型、部署 ComfyUI 服务进行在线推理。
前置要求
您需先开通文件存储和云服务器,后续模型需要存储到文件系统中,上传需要依赖云服务器。
一、构建自定义镜像
本节为您介绍,如何基于平台基础镜像构建自定义镜像,并上传到自定义镜像仓库,进行部署服务使用。
平台基础镜像
\1. 内置特性如下:
内置图生视频插件 ComfyUI-VideoHelperSuite
内置 SD 模型 v1-5-pruned-emaonly.ckpt
\2. 获取镜像:
基础镜像为:
cc.ccs.tencentyun.com/tione-public-images/ti-cloud-stable-diffusion-webui:comfyui-v0.0.1-062483
拉取到本地:
docker pull ccr.ccs.tencentyun.com/tione-public-images/ti-cloud-stable-diffusion-webui:comfyui-v0.0.1-062483
说明:
\1. Comfyui 社区版本,可单击跳转。
\2. 本文示例使用的 commit 号:062483823738ed610d8d074ba63910c90e9d45b7。
构建自定义镜像
\1. 以下用自定义镜像 ccr.ccs.tencentyun.com/test/stable-diffusion-webui:comfyui-1.0.1,举例说明:
自定义镜像 Dockerfile。
FROM ccr.ccs.tencentyun.com/tione-public-images/ti-cloud-stable-diffusion-webui:comfyui-v0.0.1-062483
ENV DEBIAN_FRONTEND=noninteractive PIP_PREFER_BINARY=1
ENV ROOT=/stable-diffusion
##### ----- 【您按需进行替换: Begin】 ---------
# already exit ComfyUI codes in base image
RUN rm -rf ${ROOT}
RUN --mount=type=cache,target=/root/.cache/pip \
git clone https://github.com/comfyanonymous/ComfyUI.git ${ROOT} && \
cd ${ROOT} && \
git checkout master && \
git reset --hard 062483823738ed610d8d074ba63910c90e9d45b7 && \
pip install -r requirements.txt
##### ----- 【您按需进行替换: End】 ---------
WORKDIR ${ROOT}
RUN chmod u+x /docker/entrypoint.sh && cp /docker/extra_model_paths.yaml ${ROOT}
ENV NVIDIA_VISIBLE_DEVICES=all PYTHONPATH="${PYTHONPATH}:${PWD}" CLI_ARGS=""
EXPOSE 7860
ENTRYPOINT ["/docker/entrypoint.sh"]
CMD python -u main.py --listen --port 8501 ${CLI_ARGS}
构建自定义镜像。
您需要将ccr.ccs.tencentyun.com/test/stable-diffusion-webui:comfyui-1.0.1 替换为自己的镜像仓库名称:
docker build -f Dockerfile -t ccr.ccs.tencentyun.com/test/stable-diffusion-webui:comfyui-1.0.1 .
将自定义镜像推送至镜像仓库。
二、模型导入
第一步:前置准备,购买 CVM 和 CFS
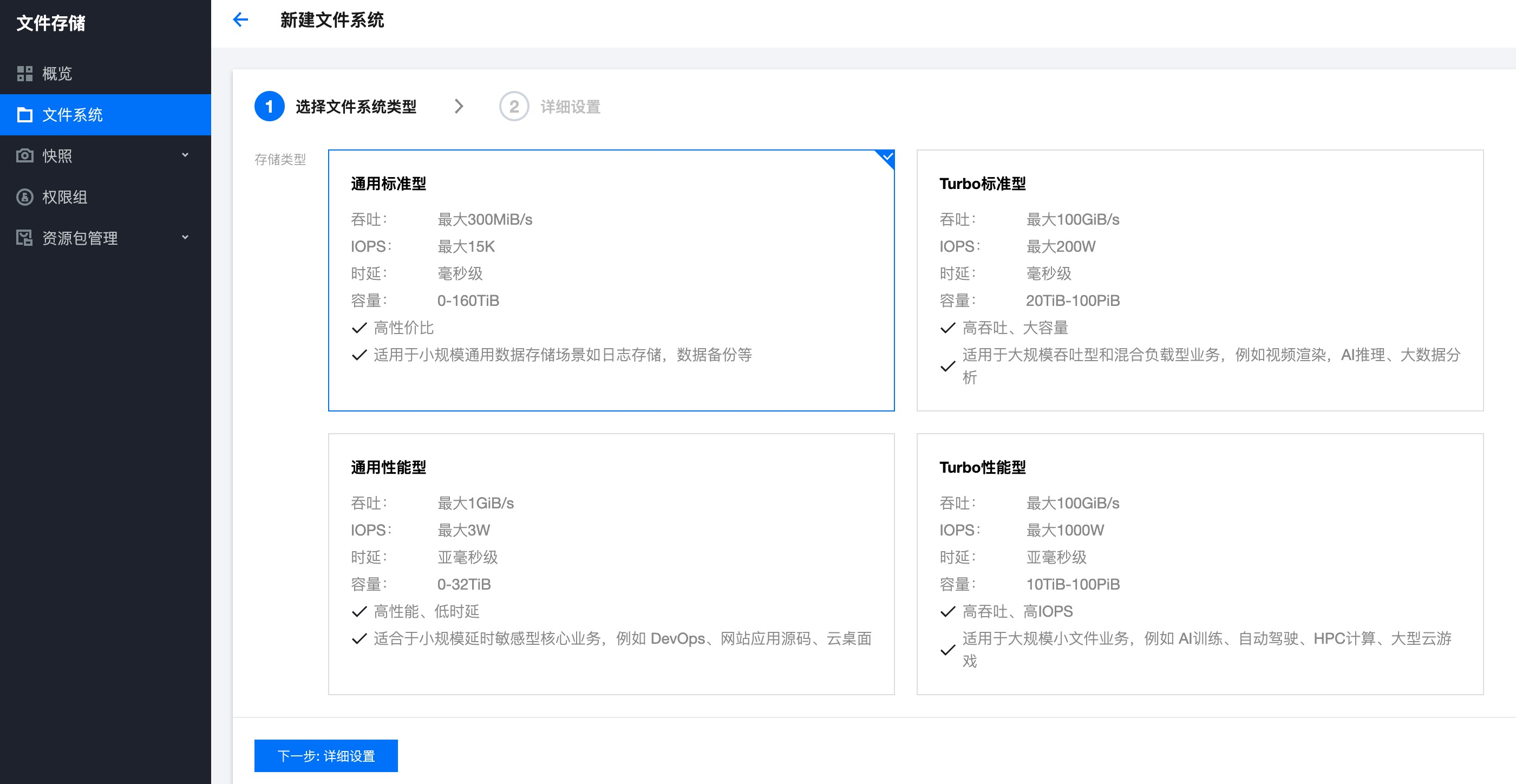
\1. 登录 CFS 控制台,在左侧导航栏中选择文件系统,单击创建,选择您需要的存储类型,完成对应配置。
\2. 登录 CFS 控制台,在左侧导航栏中选择实例,单击新建,进行购买。
说明:
\1. CFS、CVM 地域请选择 TIONE 支持的地域:北京、上海、广州。
\2. CFS、CVM 网络请保持一致。
\3. 在 CVM 上挂载 CFS,可参考 在 Windows 客户端上使用 CFS 文件系统。
示例可参考:
sudo mount -t nfs -o vers=4.0,noresvport 192.168.0.14:/ /data
第二步:将模型上传到 CFS
假设 ${CFS_DIR} 为 CFS 挂载目录,如示例 ${CFS_DIR} = /data/comfyui:
\1. 基础模型存放在 ${CFS_DIR}/models/Stable-diffusion 下,当此路径下无模型时,平台会使用内置模型 v1-5-pruned-emaonly.ckpt。
\2. 插件存放在 ${CFS_DIR}/config/model/config/comfy/custom_nodes 下,平台镜像中内置了插件 ComfyUI-VideoHelperSuite。
\3. 模型元信息存放在 ${CFS_DIR}/.cache 下,平台镜像中内置了 hugging face models–openai–clip-vit-large-patch14。
说明:
因涉及 Hugging Face 的软件许可和合规问题,平台上无法访问访问 Hugging Face 等外网,因此模型涉及的元信息需手动存放至此。
\4. Lora 等目录结构可同 stable diffusion webui, 均存放至 ${CFS_DIR}/models/ 下。

三、服务部署
\1. 登录 TI-ONE 控制台,在左侧导航栏中选择模型服务 > 在线服务,单击**新建服务,**进入新建页面。
\2. 您可填写服务名称,模型来源选择“CFS”,选择该地域下的 CFS,CFS 挂载路径为自定义的模型所在路径(例如 comfyiui),运行环境选择自定义,选择算力,配置其他您需要的信息,单击启动服务,当您服务状态为运行中时,即部署完成,可进行推理。
四、UI 界面使用
您部署好服务后,在服务列表页的服务管理,操作里会出现打开 WebUI 页面按钮。

案例一:文生图
\1. ComfyUI 示例如下:
\2. 单击“Queue Prompt” 进行生图,如下图:
案例二:图生视频
\1. 将 svd 模型文件上传至CFS ${CFS_DIR}/models/Stable-diffusion。
说明:
svd 模型文件,您可单击下载。
\2. 如 模型导入第二步 所述,将 svd 模型文件放在 /models/Stable-diffusion 路径下。
\3. 打开界面,上传 workflow,图生视频的工作流示例如下:
说明:
workflow.json文件,您可单击下载。
\4. 单击“Queue Prompt” 进行推理,得到视频,如下:
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

科技之力与好奇之心,共建有温度的智能世界
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)