
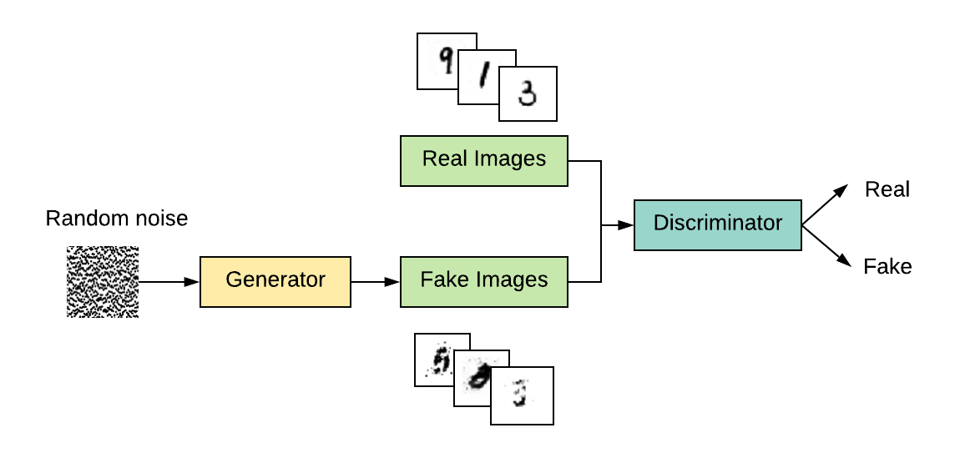
利用生成对抗网络(GAN)实现自建数据集的图像生成
从建立数据集到保存模型以及检测生成效果,全部包含在内……
·
利用Pytorch框架实现的自建数据集,将要生成的原始图片导入到train_data文件,运行主程序即可,so easy~
同时也会保存训练好的生成网络,只需运行对应的test.py即可
#主程序文件,用于训练模型
import argparse
import os
import numpy as np
import math
# import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from tools.my_dataset import myDataset
import torch
os.makedirs("train_images", exist_ok=True)
os.makedirs("save_Model", exist_ok=True)
PATH='D:\Code\Program\Python_Code\GAN\gan_name'
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=2, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each train_images dimension")
parser.add_argument("--channels", type=int, default=3, help="number of train_images channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen train_images samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 损失函数
adversarial_loss = torch.nn.BCELoss()
#定义生成器和判别器
generator = Generator()
discriminator = Discriminator()
dataset = r'D:\Code\Program\Python_Code\GAN\gan_name'
train_data_directory = os.path.join(dataset, 'train_data')
image_transforms = {
'train_data': transforms.Compose([
transforms.Resize([opt.img_size,opt.img_size]),
transforms.ToTensor(),
])
}
data = {
'train_data': myDataset(data_dir=train_data_directory,
transform=image_transforms['train_data'])
}
dataloader = DataLoader(data['train_data'], batch_size=opt.batch_size, shuffle=True)
train_data_data_size = len(data['train_data'])
print('train_size: {:4d} '.format(train_data_data_size))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.FloatTensor
# ----------
# 开始训练
# ----------
ans=0
for epoch in range(opt.n_epochs):
# for i, (imgs, _) in enumerate(dataloader):
for i, imgs in enumerate(dataloader):
#真实图像来自于train_data
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# 真实图像
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 噪声输入
z = Variable(Tensor(np.random.normal(0, 3, (imgs.shape[0], opt.latent_dim))))
# 生成图像
gen_imgs = generator(z)
# 计算G_损失
aa = discriminator(gen_imgs)
g_loss = adversarial_loss(aa, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# 训练判别器
# ---------------------
optimizer_D.zero_grad()
# 测量判别器检测假图像的能力
bb = discriminator(real_imgs)
real_loss = adversarial_loss(bb, valid)
# 此处需要注意,detach()是为了截断梯度流,不计算生成网络的损失,
# 因为d_loss包含了fake_loss,回传的时候如果不做处理,默认会计算generator的梯度,
# 而这里只需要计算判别网络的梯度,更新其权重值,生成网络保持不变即可。
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % 4000 == 0:
save_image(gen_imgs.data[:25], "D:\Code\Program\Python_Code\GAN\gan_name\\train_images\%d.png" % batches_done, nrow=5, normalize=True)
#保存模型
ans+=1
torch.save(generator, './save_Model/generator%d.pth' %ans)训练完成以后,将保存好的模型调用一下,展示训练效果:
import argparse
import os
import numpy as np
import math
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from tools.my_dataset import myDataset
import torch
#生成图片大小
img_shape = (3, 128,128)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
#创建保存图片位置
if not os.path.isdir("test_image"):
os.mkdir("test_image")
#加载模型
generator=torch.load('generator.pth');
Tensor = torch.FloatTensor
# 噪声输入
z = Variable(Tensor(np.random.normal(0, 3, (2, 100))))
# 生成图像
gen_imgs = generator(z)
save_image(gen_imgs.data[:25], "test_image/test_7_16_14.png", nrow=5, normalize=True)展示一下生成网络的生成图像效果:

训练效果相当不错(自吹自擂)
代码文件已经发到GitHub,欢迎star……

科技之力与好奇之心,共建有温度的智能世界
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)