
现代循环神经网络:双向循环神经网络
双向循环神经网络(Bidirectional Recurrent Neural Network,简称BRNN)是一种能够处理序列数据的神经网络,它能够在一个序列数据中同时考虑过去和未来的信息。与传统的循环神经网络(RNN)不同的是,BRNN在每个时间步上使用两个独立的循环结构,一个用于从过去到未来的传递信息,另一个用于从未来到过去的传递信息。
双向循环神经网络
双向循环神经网络(Bidirectional Recurrent Neural Network,简称BRNN)是一种能够处理序列数据的神经网络,它能够在一个序列数据中同时考虑过去和未来的信息。与传统的循环神经网络(RNN)不同的是,BRNN在每个时间步上使用两个独立的循环结构,一个用于从过去到未来的传递信息,另一个用于从未来到过去的传递信息。
BRNN 的主要思想是将输入序列分别从两个方向(前向和后向)进行处理,然后将它们的输出合并起来。这样,BRNN 可以利用序列中所有的信息,包括过去和未来,从而更好地捕捉序列中的长期依赖关系。比如,在自然语言处理中,BRNN可以处理由左到右和由右到左的文本序列,提高文本表示的质量,从而提高模型的性能。
隐马尔可夫模型中的动态规划
隐马尔可夫模型(Hidden Markov Model,HMM)是一种用于建模序列数据的概率模型,常用于语音识别、自然语言处理、生物信息学等领域。HMM假设每个观测数据是由一个隐含状态序列和一个与状态相关的观测序列组成。其中,隐含状态序列是一个马尔可夫过程,即每个状态只与前一个状态有关。观测序列是由各个状态生成的观测数据序列。
在HMM中,通常采用前向算法和后向算法来计算给定观测序列的概率。这两种算法都使用动态规划来解决。
前向算法用于计算观测序列
O
=
(
o
1
,
o
2
,
.
.
.
,
o
T
)
O=(o_1, o_2, ..., o_T)
O=(o1,o2,...,oT) 在模型
λ
=
(
π
,
A
,
B
)
\lambda = (\pi, A, B)
λ=(π,A,B) 下的概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。它的基本思想是在每个时间步
t
t
t,计算在已知前面所有观测值
o
1
,
o
2
,
.
.
.
,
o
t
−
1
o_1, o_2, ..., o_{t-1}
o1,o2,...,ot−1 的情况下,系统处于状态
i
i
i 的概率
α
t
(
i
)
\alpha_t(i)
αt(i)。这个概率可以通过递推计算得到。具体而言,对于
t
=
1
t=1
t=1,我们有
α
1
(
i
)
=
π
i
b
i
(
o
1
)
\alpha_1(i) = \pi_i b_i(o_1)
α1(i)=πibi(o1)
对于
t
>
1
t>1
t>1,我们有
α
t
(
i
)
=
[
∑
j
=
1
N
α
t
−
1
(
j
)
a
j
i
]
b
i
(
o
t
)
\alpha_t(i) = \left[\sum_{j=1}^N \alpha_{t-1}(j)a_{ji}\right] b_i(o_t)
αt(i)=[j=1∑Nαt−1(j)aji]bi(ot)
其中, N N N 是隐含状态的数量, a i j a_{ij} aij 表示从状态 i i i 转移到状态 j j j 的概率, b i ( o t ) b_i(o_t) bi(ot) 表示在状态 i i i 生成观测 o t o_t ot 的概率。
通过递推计算 α t ( i ) \alpha_t(i) αt(i),最终可以得到 P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda) = \sum_{i=1}^N \alpha_T(i) P(O∣λ)=∑i=1NαT(i)。
后向算法用于计算给定观测序列
O
O
O 和模型
λ
\lambda
λ 下,系统处于状态
i
i
i 的概率
β
t
(
i
)
\beta_t(i)
βt(i)。后向算法的基本思想是在已知后面所有观测值
o
t
+
1
,
o
t
+
2
,
.
.
.
,
o
T
o_{t+1}, o_{t+2}, ..., o_T
ot+1,ot+2,...,oT 的情况下,系统处于状态
i
i
i 的概率。具体而言,对于
t
=
T
t=T
t=T,我们有
β
T
(
i
)
=
1
\beta_T(i) = 1
βT(i)=1
对于
t
<
T
t<T
t<T,我们有
β
t
(
i
)
=
∑
j
=
1
N
a
i
j
b
j
(
o
t
+
1
)
β
t
+
1
(
j
)
\beta_t(i) = \sum_{j=1}^N a_{ij} b_j(o_{t+1}) \beta_{t+1}(j)
βt(i)=j=1∑Naijbj(ot+1)βt+1(j)
通过递推计算 β t ( i ) \beta_t(i) βt(i),可以得到 P ( O ∣ λ ) = ∑ i = 1 N π i b i ( o 1 ) β 1 ( i ) P(O|\lambda) = \sum_{i=1}^N \pi_i b_i(o_1) \beta_1(i) P(O∣λ)=∑i=1Nπibi(o1)β1(i)。
同时,前向算法和后向算法还可以用来计算给定观测序列和模型,系统处于某一状态 i i i 的概率 γ t ( i ) \gamma_t(i) γt(i) 和从状态 i i i 到状态 j j j 的转移概率 ξ t ( i , j ) \xi_t(i,j) ξt(i,j)。具体而言,对于 t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T,我们有
γ t ( i ) = α t ( i ) β t ( i ) P ( O ∣ λ ) \gamma_t(i) = \frac{\alpha_t(i) \beta_t(i)}{P(O|\lambda)} γt(i)=P(O∣λ)αt(i)βt(i)
ξ t ( i , j ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) P ( O ∣ λ ) \xi_t(i,j) = \frac{\alpha_{t}(i) a_{ij} b_j(o_{t+1}) \beta_{t+1}(j)}{P(O|\lambda)} ξt(i,j)=P(O∣λ)αt(i)aijbj(ot+1)βt+1(j)
其中, P ( O ∣ λ ) P(O|\lambda) P(O∣λ) 是观测序列 O O O 在模型 λ \lambda λ 下的概率。
动态规划在HMM中的应用,使得我们可以高效地计算观测序列的概率,以及在给定观测序列的情况下,系统处于某一状态的概率和转移概率。这对于模型训练和预测都非常有帮助。
双向模型
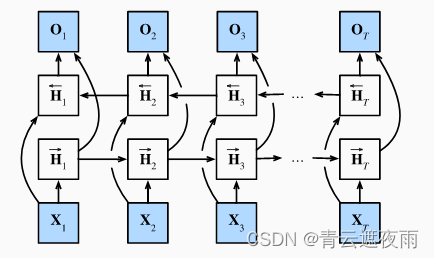
如果我们希望在循环神经网络中拥有一种机制, 使之能够提供与隐马尔可夫模型类似的前瞻能力, 我们就需要修改循环神经网络的设计。 幸运的是,这在概念上很容易, 只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络, 而不是只有一个在前向模式下“从第一个词元开始运行”的循环神经网络。 双向循环神经网络(bidirectional RNNs) 添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。 下图描述了具有单个隐藏层的双向循环神经网络的架构。

数学定义
正向隐藏状态:
H
→
t
=
ϕ
(
X
t
W
x
h
+
H
→
t
−
1
W
h
h
+
b
h
)
H_{\rightarrow t} = \phi(X_t W_{xh} + H_{\rightarrow t-1} W_{hh} + b_h)
H→t=ϕ(XtWxh+H→t−1Whh+bh)
反向隐藏状态:
H
←
t
=
ϕ
(
X
t
W
x
h
+
H
←
t
+
1
W
h
h
+
b
h
)
H_{\leftarrow t} = \phi(X_t W_{xh} + H_{\leftarrow t+1} W_{hh} + b_h)
H←t=ϕ(XtWxh+H←t+1Whh+bh)
输出:
O
t
=
H
t
W
h
q
+
b
q
O_t = H_t W_{hq} + b_q
Ot=HtWhq+bq
其中,
X
t
X_t
Xt 是输入,
W
x
h
,
W
h
h
,
W
h
q
W_{xh}, W_{hh}, W_{hq}
Wxh,Whh,Whq 是权重矩阵,
b
h
,
b
q
b_h, b_q
bh,bq 是偏置项,
ϕ
\phi
ϕ 是激活函数,
H
→
t
H_{\rightarrow t}
H→t和
H
←
t
H_{\leftarrow t}
H←t 是正向和反向的隐藏状态,
H
t
=
[
H
→
t
;
H
←
t
]
H_t = [H_{\rightarrow t}; H_{\leftarrow t}]
Ht=[H→t;H←t] 是双向隐藏状态,
O
t
O_t
Ot 是输出。
模型的计算代价及其应用
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。 也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。 但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。 因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么, 所以将不会得到很好的精度。 具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词; 而在测试期间,我们只有过去的数据,因此精度将会很差。 下面的实验将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。 其主要原因是网络的前向传播需要在双向层中进行前向和后向递归, 并且网络的反向传播还依赖于前向传播的结果。 因此,梯度求解将有一个非常长的链。
缺陷!!
由于双向循环神经网络使用了过去的和未来的数据, 所以我们不能盲目地将这一语言模型应用于任何预测任务。 尽管模型产出的困惑度是合理的, 该模型预测未来词元的能力却可能存在严重缺陷。 我们用下面的示例代码引以为戒,以防在错误的环境中使用它们。
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)



科技之力与好奇之心,共建有温度的智能世界
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)