
循环神经网络(RNN)简介与应用
循环神经网络(Recurrent Neural Networks,简称RNN)是深度学习中用于处理序列数据的一类神经网络。本文将介绍RNN的基本概念、原理、以及在不同领域的应用,并附带一些具体的代码实例,以便更好地理解和应用这一强大的序列模型。
循环神经网络(RNN)简介与应用
循环神经网络(Recurrent Neural Networks,简称RNN)是深度学习中用于处理序列数据的一类神经网络。本文将介绍RNN的基本概念、原理、以及在不同领域的应用,并附带一些具体的代码实例,以便更好地理解和应用这一强大的序列模型。
一、RNN基本概念
RNN 的核心设计理念是利用序列信息。它通过隐藏层的状态保持来处理序列中的相关信息,适宜于处理时间序列数据或自然语言文本。
二、RNN原理解析
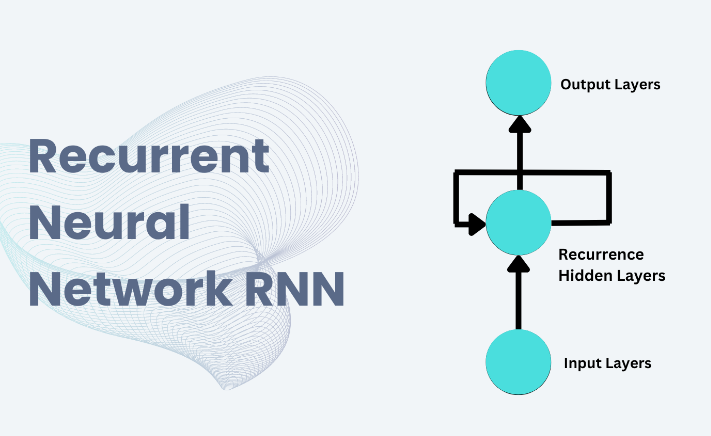
2.1 RNN网络结构
循环神经网络(RNN)是一种对时间序列数据具有强大建模能力的神经网络结构。这种网络结构设计出来是为了捕捉数据中的时间动态信息。本文将详尽解释RNN的网络结构,包括其核心概念、主要组件以及数据流向。
RNN网络主要组件
输入层(Input),隐藏层(Hidden State),输出层(Output)
RNN的基础结构包含三个主要部分:输入层、隐藏层和输出层。输入层接受序列中的每个元素,隐藏层存储序列的历史信息,输出层根据隐藏状态生成相应的输出。
循环单元(Recurrent Unit)
RNN的核心是循环单元,它定义了如何更新隐藏状态。在每一个时间步,循环单元都会结合当前输入和上一时刻的隐藏状态来更新当前的隐藏状态。
权重参数(Weights)和偏置项(Bias)
RNN中的每一个循环单元都有其权重和偏置项,它们会在训练过程中被优化。这些参数共同决定了RNN如何在给定的输入和前一隐藏状态的情况下更新当前隐藏状态。
RNN的数据流向
时间步展开(Unrolling in Time)
为了更清楚地展示数据是如何在RNN中流动的,常将RNN按时间步展开。这意味着我们将网络沿时间轴展开,每个时间步都显示网络的一个副本。
隐藏状态传递(Hidden State Propagation)
在时间步( t )中,隐藏层会接收来自时间步( t-1 )的隐藏状态和当前时间步的输入。这样的设计允许网络在内部存储信息,并在整个序列中传递这些信息。
输出计算(Output Computation)
隐藏状态被更新后,可以用来计算当前时间步的输出。通常情况下,输出是基于隐藏状态的函数,可能还会经过某种形式的转换,如线性层或者激活函数。
代码示例:RNN的前向传播
以下是一个简单的RNN前向传播的Python代码示例,使用PyTorch框架。
import torch
import torch.nn as nn
# 定义简单的RNN单元
class SimpleRNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleRNNCell, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = torch.tanh(self.i2h(combined))
return hidden
# 初始化参数
input_size = 4
hidden_size = 8
seq_len = 5
batch_size = 1
# 创建RNN单元和初始隐藏状态
rnn_cell = SimpleRNNCell(input_size, hidden_size)
hidden = torch.zeros(batch_size, hidden_size)
# 生成一个简单的随机输入序列
inputs = torch.randn(seq_len, batch_size, input_size)
# 循环处理输入序列
for i in range(seq_len):
# 更新隐藏状态
hidden = rnn_cell(inputs[i], hidden)
上述代码中的SimpleRNNCell是一个自定义的RNN单元,它使用线性层和tanh激活函数来更新隐藏状态。
2.2 RNN的数学模型
RNN每个时刻的输出依赖于当前输入和上一时刻的隐藏状态,数学公式通常可以表示为:
h t = f U ( h t − 1 ) + W x t h_t = f_U(h_{t-1}) + Wx_t ht=fU(ht−1)+Wxt
y t = f V ( h t ) y_t = f_V(h_t) yt=fV(ht)
其中( h_t )是当前时刻的隐藏状态,( x_t )是当前时刻的输入,( y_t )是当前时刻的输出,( f_U )、( f_V )和( W )是网络参数。
2.3 RNN的梯度消失和梯度爆炸问题
由于RNN纯依赖隐藏状态递归传递,存在梯度消失和梯度爆炸的问题,这限制了RNN在时间序列较长的任务上的应用。
三、RNN的变种和改进
RNN变种和改进的完整解析
循环神经网络(RNN)由于其对序列数据的先天适应能力,在多个领域得到了成功的应用。然而,在实践中,传统的RNN结构容易出现梯度消失和梯度爆炸的问题,这极大限制了其处理长序列数据的能力。因此,研究者们提出了多种RNN的变体来解决这些挑战。本文将详细介绍最常见的RNN变体和改进方案。
一、LSTM(长短期记忆网络)
LSTM是一种特殊的RNN结构,它通过引入门控机制来避免梯度消失问题,并保持长期的序列依赖关系。LSTM的关键在于其单元结构,每个单元包含输入门、遗忘门、输出门三个部分。
1.1 输入门(Input Gate)
输入门负责控制当前输入( x_t )进入单元的信息量。它由两部分组成:一个sigmoid神经网络和一个tanh神经网络。sigmoid网络决定留下多少信息,tanh网络则产生新的候选值,这些值将可能被添加到单元状态。
1.2 遗忘门(Forget Gate)
遗忘门决定了保留多少上一时刻的单元状态( C_{t-1} )。它同样由一个sigmoid神经网络组成。如果遗忘门输出的值接近1,则保留更多旧状态;若输出接近0则丢弃更多。
1.3 输出门(Output Gate)
输出门负责基于单元状态( C_t )和输出门自身的激活度,确定最终的输出( h_t )。这里也是一个sigmoid网络来确定输出哪些部分,并通过tanh来处理单元状态,最后将两者相乘得到输出。
二、GRU(门控循环单元)
GRU是另一种RNN的变体,它简化了LSTM的结构,将输入门和遗忘门合并为更新门,并去除了输出门,直接输出隐藏状态。
2.1 更新门(Update Gate)
更新门帮助模型决定以多大程度上保留之前的隐藏状态,并引入新的隐藏状态。这相当于是决定记忆过去信息的多少,以及接受多少新的信息。
2.2 重置门(Reset Gate)
重置门则用来决定保留多少过去的记忆。如果重置门的值接近0,就意味着“忘记”过去完全依赖当前的输入。
三、双向RNN(Bi-directional RNN)
双向RNN通过在原始序列的基础上增加对时间序列的逆向传递来富集序列的上下文信息。这种结构包含两个RNN层,正向RNN层处理正向序列,逆向RNN层处理反向序列,最终的输出是这两个RNN层输出的连接。
四、Peephole LSTM
Peephole LSTM是LSTM的一个变体,在传统的LSTM结构中,输入门、遗忘门、输出门的激活只依赖于前一时刻的隐藏状态和当前的输入。Peephole LSTM给门控信号增加了一个窥视孔,允许门控信号直接查看单元状态。
这些变体和改进使得RNN能够更有效地处理长序列数据,并在复杂的序列建模任务中取得了更好的性能。这些结构的提出极大拓展了RNN在深度学习中的应用领域,尤其是在序列预测、自然语言理解和语音识别等任务中。
四、RNN在不同领域的应用
4.1 自然语言处理(NLP)
在自然语言处理中,RNN常被用于语言模型、机器翻译、文本分类等任务。
4.2 音频和视频处理
在音频和视频处理方面,RNN可以用于语音识别、音乐生成等。
4.3 时间序列预测
RNN在股票价格预测、天气预测等时间序列分析任务中也有广泛应用。
五、代码实例
以下是一个简单的RNN在PyTorch中的实现代码示例:
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
input_size = 5
hidden_size = 10
output_size = 3
rnn = SimpleRNN(input_size, hidden_size, output_size)
这段代码定义了一个简单的RNN模型,它包含一个隐藏层,并且可以用于分类任务。
参考文献
-
Medsker, L. R., & Jain, L. C. (2001). Recurrent Neural Networks: Design and Applications. Retrieved from Academia.edu
-
Grossberg, S. (2013). Recurrent neural networks. Scholarpedia. Retrieved from Scholarpedia.org
-
Salehinejad, H., Sankar, S., Barfett, J., Colak, E., & Valaee, S. (2017). Recent Advances in Recurrent Neural Networks. arXiv preprint arXiv:1801.01078. Retrieved from arXiv.org
-
Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing. Retrieved from IEEE Xplore
-
Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. In International Conference on Machine Learning. Retrieved from MLR.press
-
Sutskever, I. (2013). Training recurrent neural networks. Retrieved from University of Toronto
-
Bullinaria, J. A. (2013). Recurrent neural networks. Neural Computation Lecture, University of Birmingham. Retrieved from University of Birmingham
-
Sutskever, I., Martens, J., & Hinton, G. E. (2011). Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11). Retrieved from University of Toronto
-
Lipton, Z. C., Berkowitz, J., & Elkan, C. (2015). A critical review of recurrent neural networks for sequence learning. arXiv preprint arXiv:1506.00019. Retrieved from arXiv.org

科技之力与好奇之心,共建有温度的智能世界
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)