
演唱会真假难辨?一招揭密声纹技术丨ZA科技事儿
技术的发展总是一把双刃剑,剑锋所向也是人心的选择,无论技术如何发展,希望我们能像孙燕姿说得那样“我认为思想纯净、做自己,已然足够”。
演唱会真假难辨?一招揭密声纹技术丨ZA科技事儿
近日,某月天演唱会被曝假唱事件引起舆论哗然。先有up主投稿开锤假唱,后有正主发声接连否认,围绕怎样算假唱?如何鉴别假唱的问题?社会各界开启了新一轮争论。
其实,除了给歌手录音修音外,和声音有关的技术已经进步了很多。
比如,随着AI技术的迅速发展,声线与明星相似的AI歌手也出现在大众视野。B站上几乎条条百万播放的AI孙燕姿演唱,就是运用了训练好的模型,再经过顶级调音师的手笔,从而达到以假乱真的效果。

但是,声纹技术的演进给大家带来惊喜的同时,也容易被别有用心者利用。比如诈骗团伙用声音技术拨打欺诈电话,或窃取普通人的声音进行身份识别和窃取资产,其中厉害让人不寒而栗。
众安保险算法高级工程师孙杰介绍到:“分析一段声音,本质上在一段时间轴上,分析各频率声波的叠加特点。判断演唱会里的一段声音是否是现场版本,最简单的方法是看声波的线。首先去掉背景音乐,留下纯粹的人声,再看这段声波。真唱的声音会有不规则波动,包括音准、响度、音色等方面。而经过处理过的版本,显得特别规律,就像一张实拍的图片被过度美颜成不真实的样子。“

(众安保险算法高级工程师孙杰)
使用科技手段修音并不是罕见的事情,小到KTV唱歌,大各公司组织的年会,为了更好的演出效果都用过类似的处理技术。

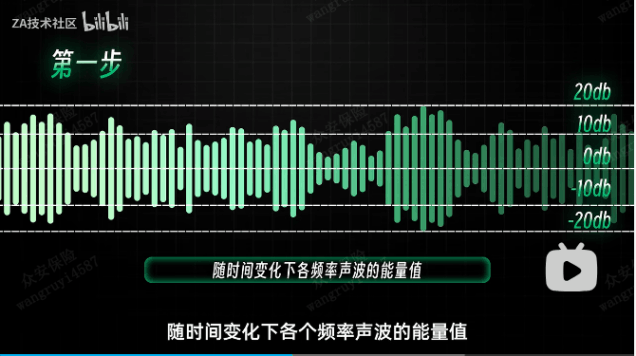
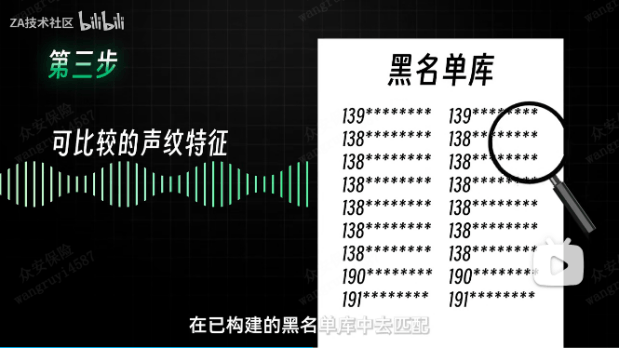
孙杰表示:”老实说,判断一通诈骗电话,比鉴定演唱真假唱更难。在自然电话通话过程中,用户的通话内容不可预知,且包含低质量的段落,这给声纹识别工作造成了一定的阻碍。从具体步骤来说,识别一段声音分为3步,
一是语谱图,输入一段声音声音原始文件,从频谱分析角度得到随时间变化下各频率声波的能量值;
二是深度学习模型处理,将输入的声纹统一映射到一个特征空间,将声音信息转化为可比较的声纹特征;

三是特征比对,在已构建的黑名单库中去匹配是否有接近的历史通话。“
梅尔语谱图是现在最常用的声纹特征分析方式, 声音文件记录的原始信息可以简化理解为是一段时间内采样到的声波振动规律,延时间轴来看是一段在零轴上下起伏的波形。具体方法是将语音切分成极小的时间跨度,在每个跨度内做短时傅立叶变换(STFT)得到各频率能量表示,再将完整的时间跨度的结果拼起来得到完整的语谱图(spectrogram)。

另一个问题是,人耳在聆听时,对低频差异区分能力要高于高频。为了更接近人耳的区分能力,语谱图可以对声波频率做映射,加大低频区域的区分度。我们常用的梅尔语谱图就是这个原理。
孙杰进一步解释到:”这里和大家具体解释一下声纹识别技术,如果有一个坐标系,我们很难做到把100段录音很合理地放进一个坐标系中,使得两录音与坐标之间的距离一定与其相似程度成正比。但反过来说实现了这件事,那么衡量声纹之间的相似度就易如反掌了。我们可以将其中的深度学习模型简化理解为一个非常复杂的数学公式,功能是将任意输入映射到我们指定的特征空间。”
通过设计和训练代理任务,使它学习数据集中在我们人难以归纳的特征。通过大量训练,模型能掌握如何从输入数据中寻找蛛丝马迹,提取各种浅层到深层特征,自动把握各个特征表达的区分度,并映射到新的特征空间。

最后,技术的发展总是一把双刃剑,剑锋所向也是人心的选择,无论技术如何发展,希望我们能像孙燕姿说得那样“我认为思想纯净、做自己,已然足够”。


科技之力与好奇之心,共建有温度的智能世界
更多推荐


 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)