
【Pytorch深度学习实战】(11)变分自动编码器(VAE)
而变分自编码器便是用“取值的概率分布”代替原先的单值来描述对特征的观察的模型,如下图的右边部分所示,经过变分自编码器的编码,每张图片的微笑特征不再是自编码器中的单值而是一个概率分布。另一个根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布,称为生成网络。在上面的模型中,经过反复训练,我们的输入数据X最终被转化为一个编码向量X’, 其中X’的每个维度表示一些学到的关于数据的特征,而X’在每
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
Variational AutoEncoder(VAE)原理
传统的自编码器模型主要由两部分构成:编码器(encoder)和解码器(decoder)。如下图所示:

在上面的模型中,经过反复训练,我们的输入数据X最终被转化为一个编码向量X’, 其中X’的每个维度表示一些学到的关于数据的特征,而X’在每个维度上的取值代表X在该特征上的表现。随后,解码器网络接收X’的这些值并尝试重构原始输入。
举一个例子来加深大家对自编码器的理解:
假设任何人像图片都可以由表情、肤色、性别、发型等几个特征的取值来唯一确定,那么我们将一张人像图片输入自动编码器后将会得到这张图片在表情、肤色等特征上的取值的向量X’,而后解码器将会根据这些特征的取值重构出原始输入的这张人像图片。

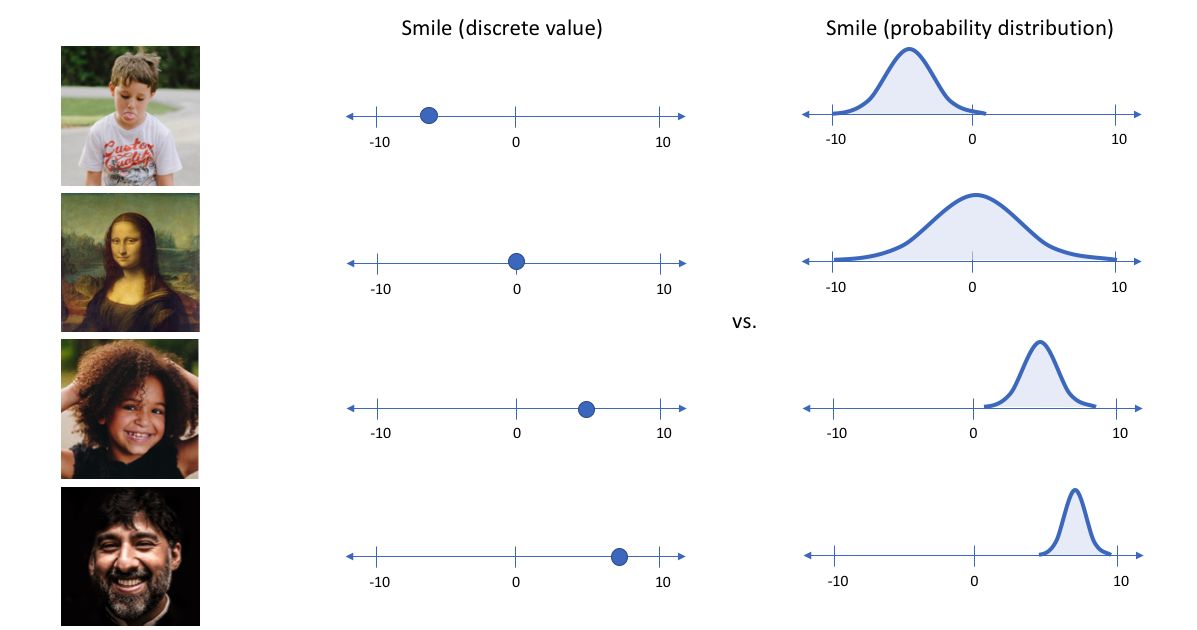
在上面的示例中,我们使用单个值来描述输入图像在潜在特征上的表现。但在实际情况中,我们可能更多时候倾向于将每个潜在特征表示为可能值的范围。例如,如果输入蒙娜丽莎的照片,将微笑特征设定为特定的单值(相当于断定蒙娜丽莎笑了或者没笑)显然不如将微笑特征设定为某个取值范围(例如将微笑特征设定为x到y范围内的某个数,这个范围内既有数值可以表示蒙娜丽莎笑了又有数值可以表示蒙娜丽莎没笑)更合适。而变分自编码器便是用“取值的概率分布”代替原先的单值来描述对特征的观察的模型,如下图的右边部分所示,经过变分自编码器的编码,每张图片的微笑特征不再是自编码器中的单值而是一个概率分布。

通过这种方法,我们现在将给定输入的每个潜在特征表示为概率分布。当从潜在状态解码时,我们将从每个潜在状态分布中随机采样,生成一个向量作为解码器模型的输入。

通过上述的编解码过程,我们实质上实施了连续,平滑的潜在空间表示。对于潜在分布的所有采样,我们期望我们的解码器模型能够准确重构输入。因此,在潜在空间中彼此相邻的值应该与非常类似的重构相对应。

以上便是变分自编码器构造所依据的原理,我们再来看一看它的具体结构。

如上图所示,与自动编码器由编码器与解码器两部分构成相似,VAE利用两个神经网络建立两个概率密度分布模型:一个用于原始输入数据的变分推断,生成隐变量的变分概率分布,称为推断网络;另一个根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布,称为生成网络。
假设原始数据集为

,每个数据样本 xi 都是随机产生的相互独立、连续或离散的分布变量,生成数据集合为

,并且假设该过程产生隐变量Z ,即Z是决定X属性的神秘原因(特征)。其中可观测变量X 是一个高维空间的随机向量,不可观测变量 Z 是一个相对低维空间的随机向量,该生成模型可以分成两个过程:
(1)隐变量 Z 后验分布的近似推断过程:

,即推断网络。
(2)生成变量X' 的条件分布生成过程:

,即生成网络。
尽管VAE 整体结构与自编码器AE 结构类似,但VAE 的作用原理和AE 的作用原理完全不同,VAE 的“编码器”和“解码器” 的输出都是受参数约束变量的概率密度分布,而不是某种特定的编码。
变分自编码器Pytorch的实现
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 如果不存在则创建目录
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
# 超参数
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 15
batch_size = 128
learning_rate = 1e-3
# MNIST 数据集
dataset = torchvision.datasets.MNIST(root='../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 数据加载器
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)
# VAE模型
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h)
def reparameterize(self, mu, log_var):
std = torch.exp(log_var/2)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 开始训练
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# 前传
x = x.to(device).view(-1, image_size)
x_reconst, mu, log_var = model(x)
# 计算重建损失和kl散度
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
# 反向传播和优化
loss = reconst_loss + kl_div
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 10 == 0:
print ("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch+1, num_epochs, i+1, len(data_loader), reconst_loss.item(), kl_div.item()))
with torch.no_grad():
# 保存采样图像
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch+1)))
# 保存重建的图像
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch+1)))
科技之力与好奇之心,共建有温度的智能世界
更多推荐


 22
22 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)