
机器学习(学习笔记)——监督学习和无监督学习
机器学习可以分为两大类:监督学习和无监督学习。今天介绍机器监督学习和无监督学习。举一个简单的例子:你小时候见到了狗和猫两种动物,有人告诉你这个样子的是狗、那个样子的是猫,你学会了辨别,这是监督学习;你小时候见到了狗和猫两种动物,没人告诉你哪个是狗、哪个是猫,但你根据他们样子、体型等特征的不同鉴别出这是两种不同的生物,并对特征归类,这是无监督学习。
前言
机器学习可以分为两大类:监督学习和无监督学习。
今天介绍机器监督学习和无监督学习。
** 监督学习和无监督学习很好区分:是否有监督(supervised),就看输入数据是否有标签(label),输入数据有标签,则为有监督学习,没标签则为无监督学习。**
举一个简单的例子:你小时候见到了狗和猫两种动物,有人告诉你这个样子的是狗、那个样子的是猫,你学会了辨别,这是监督学习;你小时候见到了狗和猫两种动物,没人告诉你哪个是狗、哪个是猫,但你根据他们样子、体型等特征的不同鉴别出这是两种不同的生物,并对特征归类,这是无监督学习。
监督学习(supervised learning)
监督学习是机器学习中的一种训练方式,是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。
通俗来讲是指我们给算法一个数据集其中包涵了正确的答案·。
特点:既有输入也有结果
监督学习包含回归问题和分类问题。
回归问题
分类问题是指设法预测连续值的属性。
1.回归模型—回归模型用于输出变量为实际值的问题,例如单一的数字、美元、薪水、体重或压力。它最常用于根据先前的观测数据来预测数值。一些比较常见的回归算法包括线性回归、逻辑回归、多项式回归和脊回归。
举个例子(这里借助吴恩达视频的例子):
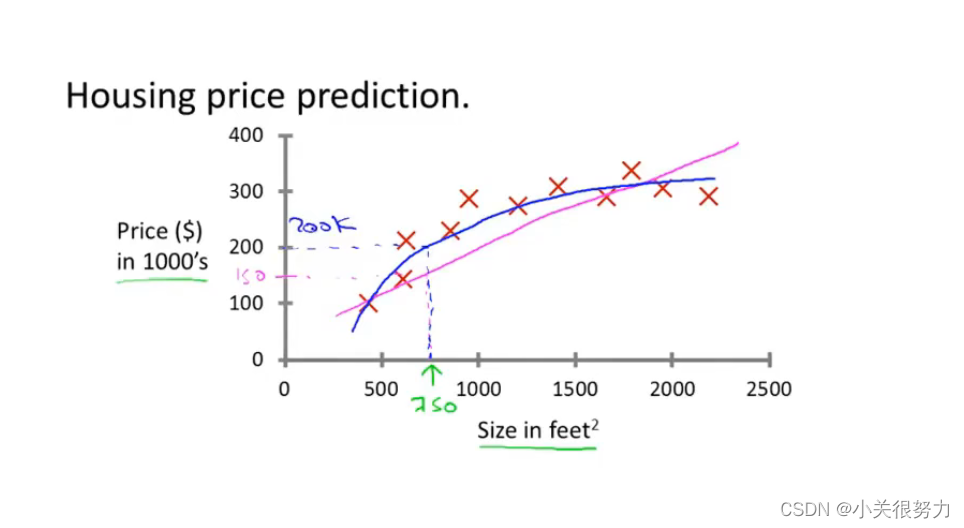
通过房地产市场的数据,预测一个给定面积的房屋的价格就是一个回归问题。这里我们可以把价格看成是面积的函数,它是一个连续的输出值。 但是,当把上面的问题改为“预测一个给定面积的房屋的价格是否比一个特定的价格高或者低”的时候,这就变成了一个分类问题, 因为此时的输出是‘高’或者‘低’两个离散的值。

分类问题
分类问题目的预测离散值的输出。
2.分类模型—分类模型用于可以对输出变量进行分类,例如“是”或“否”、“通过”或“失败”。分类模型用于预测数据的类别。现实生活中的例子包括垃圾邮件检测、情绪分析、考试记分卡预测等。
举个例子:
给定医学数据,通过肿瘤的大小来预测该肿瘤是恶性瘤还是良性瘤(课程中给的是乳腺癌的例子),这就是一个分类问题,它的输出是0或者1两个离散的值。(0代表良性,1代表恶性)。
分类问题的输出可以多于两个,比如在该例子中可以有{0,1,2,3}四种输出,分别对应{良性, 第一类肿瘤, 第二类肿瘤, 第三类肿瘤}。
下图中上下两个图只是两种画法。第一个是有两个轴,Y轴表示是否是恶性瘤,X轴表示瘤的大小; 第二个是只用一个轴,但是用了不同的标记,用O表示良性瘤,X表示恶性瘤。


在这个例子中特征只有一个,那就是瘤的大小。 有时候也有两个或者多个特征, 例如下图, 有“年龄”和“肿瘤大小”两个特征。(还可以有其他许多特征,如下图右侧所示)

无监督学习
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习,“监督”的意思可以直观理解为“是否有标注的数据”。
简单来讲就是训练机器使用即未分类也未标记的数据的方法,机器只能自行学习。
无监督学习的特点是,传递给算法的数据在内部结构中非常丰富,而用于训练的目标和奖励非常稀少。无监督学习算法学到的大部分内容必须包括理解数据本身,而不是将这种理解应用于特定任务。
1.聚类是最常见的无监督学习方法之一。聚类的方法包括将未标记的数据组织成类似的组,称为聚类。因此,聚类是相似数据项的集合。此处的主要目标是发现数据点中的相似性,并将相似的数据点分组到一个聚类中。
2.异常检测是识别与大多数数据显著不同的特殊项、事件或观测值的方法。通常在数据中寻找异常或异常值的原因在于它们是可疑的。异常检测常用于银行欺诈和医疗差错检测。
借助图文理解
在无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构。在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。在无监督学习中给定的数据没有任何标签或者说只有同一种标签。如下图所示:

如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,,这样的算法就叫聚类算法。

无监督学习举例
-
新闻分类
通过房地产市场的数据,预测一个给定面积的房屋的价格就是一个回归问题。这里我们可以把价格看成是面积的函数,它是一个连续的输出值。 但是,当把上面的问题改为“预测一个给定面积的房屋的价格是否比一个特定的价格高或者低”的时候,这就变成了一个分类问题, 因为此时的输出是‘高’或者‘低’两个离散的值
第一个例子举的是Google News的例子。Google News搜集网上的新闻,并且根据新闻的主题将新闻分成许多簇, 然后将在同一个簇的新闻放在一起。如图中红圈部分都是关于BP Oil Well各种新闻的链接,当打开各个新闻链接的时候,展现的都是关于BP Oil Well的新闻。

- 根据给定基因将人群分类
如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知道哪些是第一种类型的人,哪些是第二种类型的人等等。

接下来提出一个很有趣的问题:
鸡尾酒会问题
欢迎一起学习机器学习,文章内容是跟着吴恩达视频写的,后续会继续更新的,一起加油吧!
参考链接:

科技之力与好奇之心,共建有温度的智能世界
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)