
【计算机视觉 | 目标检测】术语理解9:AIGC的理解,对比学习,解码器,Mask解码器,耦合蒸馏,半耦合,图像编码器和组合解码器的耦合优化
【计算机视觉 | 目标检测】术语理解9:AIGC的理解,对比学习,解码器,Mask解码器,耦合蒸馏,半耦合,图像编码器和组合解码器的耦合优化
一、AIGC的理解
AIGC指的是使用人工智能技术自动生成的各类数字内容,包括文本、图像、音频、视频等。它利用机器学习模型进行智能化内容生成。
主要的技术手段包括:
- 自然语言生成(NLG):使用RNN、GPT等语言模型生成文本。
- 生成对抗网络(GAN):使用GAN生成高质量图片。
- 自动语音合成(TTS):使用seq2seq等模型生成音频。
- 自动视频生成(VTG):使用GAN等生成短视频。
- 知识图谱抽取:从知识图谱中抽取结构化数据。
主要应用场景有:
- 新闻类内容:如自动体育新闻、财经新闻等。
- 广告文案:根据产品特征自动生成文案。
- 对话内容:如智能对话机器人的回复。
- 数据增强:自动生成数据集以扩充训练集。
- 图片生成:自动生成产品图片等。
- 个性化推荐:根据用户兴趣生成个性化新闻、音乐等。
AIGC的优势主要有:大规模、低成本、快速、可控、个性化等。
也要注意AIGC的潜在风险,如仿冒欺诈、负面内容扩散、人工判断依赖等。
所以AIGC是一个需要审慎引导、治理的新兴领域。它催生了焕新的内容生产形态,也提出了新的挑战。
二、对比学习
对比学习(Contrastive Learning)是计算机视觉中一个重要的学习范式,其核心思想是通过拉近正样本的特征表示并推离负样本的特征表示,来学习有效的视觉表示。
对比学习在计算机视觉中的理解主要包含以下几个方面:
- 构造正负样本对:对每个anchor样本,选择一个正样本(不同视角的同一对象等)和多个负样本。
- 特征提取:通过CNN等手段从anchor、正负样本中提取特征表示。
- 相似度计算:计算anchor和正样本、负样本的特征表示之间的相似度。
- 损失函数:设计损失以拉近anchor和正样本的距离,并推离anchor和负样本的距离。如对比损失等。
- 表示学习:通过上述过程学到能够拉近正样本并隔离负样本的视觉特征表示。
- 数据增强:增加训练样本的视角、大小、光照等变化来丰富正负样本。
- 下游任务:学习到的视觉表示可以迁移到各种下游视觉任务中,如分类、检测等。
- 注意力机制:最近也结合了注意力机制来关注样本中的重要区域。
通过构造对比任务 extracting、比较视觉样本的表示,对比学习可以学到对视觉理解任务有效的特征表达式。它近年来 emerged 为计算机视觉领域的重要基础技术之一。
总体来说,对比学习为视觉表示学习提供了一种全新的思路。
对比学习的损失函数的构建,这里详细展开一下:
在对比学习中,损失函数的目标是减小 anchor 和正样本特征的距离,同时增大 anchor 和负样本特征的距离。这样可以学习到能区分正负样本的好的特征表达。
具体来看对比损失(contrastive loss),它的定义如下:
L
=
(
1
−
Y
)
∗
D
w
2
+
Y
∗
max
(
m
a
r
g
i
n
−
D
w
,
0
)
2
L = (1-Y) * D_w ^ 2 + Y * \max(margin - D_w, 0)^2
L=(1−Y)∗Dw2+Y∗max(margin−Dw,0)2
其中:
- Y = 1 Y=1 Y=1 如果两个样本为正样本对, Y = 0 Y=0 Y=0 如果为负样本对。
- D w D_w Dw 是两个样本的特征距离(如欧式距离)。
- margin 是一个边缘距离参数。
可以看出,当 Y = 1 Y=1 Y=1 时,即为正样本对,我们将它们的距离 D w 2 D_w^2 Dw2 直接作为损失,目标是减小 D w D_w Dw,拉近正样本距离。
当 Y = 0 Y=0 Y=0 时,即为负样本对,如果它们距离 D w D_w Dw 小于 margin,我们给予惩罚,目标是让 D w D_w Dw 大于margin,推离负样本距离。
通过同时优化这两项,我们可以学习到一个能够区分正负样本的好的特征表达。这就是对比损失的设计思路。
其他对比学习的损失函数也遵循类似的思路,通过拉近正样本距离和增大负样本距离来学习特征表达。
三、解码器
编码器-解码器(Encoder-Decoder)是一个非常常见和重要的神经网络框架,特别是在序列到序列(Seq2Seq)学习任务中被广泛使用。
编码器-解码器的工作流程可概括为:
编码器(Encoder):编码器接受一个输入序列,通过神经网络将其映射到一个特征表示中,这称为“编码向量”。编码向量是输入序列的压缩表达。
解码器(Decoder):解码器基于编码向量,逐步预测目标序列中的每个元素。在每个时间步,它按顺序生成序列的下一个元素。
Attention机制:为了建模输入和输出序列之间的依赖,解码器端通常会加入Attention机制,即在每一步为解码器提供与当前步相关的输入序列部分。
训练:完整的编码器-解码器结构会端到端进行训练,以最大化生成目标序列的概率。
例如在机器翻译任务中,编码器处理源语言句子生成编码向量,解码器基于该向量生成目标语言的翻译结果。
编码器-解码器结构显著提升了Seq2Seq任务的建模能力。它非常适合处理输入输出不等长的序列映射问题。除翻译外,也广泛用于文本摘要、对话系统等任务。
关于编码器-解码器框架中解码器的理解,我来额外说明一下:
- 解码器的作用是生成目标序列,一般通过RNN或Transformer实现。
- 解码器会逐步生成序列的每个元素,在每个时间步输出序列的下一个元素。
- 在训练过程中,解码器会根据“教师强制”(teacher forcing)使用上一时刻的真实目标元素作为当前输入,进行下一时刻的预测。
- 在推理时,解码器使用前一时刻自己生成的元素作为当前输入,进行下一时刻的预测。这称为“自回归生成”。
- 每一时刻,解码器都会接收编码器输出的编码向量作为初始隐状态输入,以传递输入序列的信息。
- 注意力机制通常会用于解码器,以模拟解码器在不同时刻对编码器输出的关注,获取相关输入信息。
- 解码器一般需要设计以下几个组件:
RNN/Self-Attention网络,处理当前输入并维护隐状态
Attention层,从编码器输出生成动态上下文向量
输出层,预测目标序列的下一个元素
- 解码器和编码器需要端到端联合训练,优化生成目标序列的概率。
总结一下,解码器在框架中负责自回归地生成目标序列,它能够充分利用输入序列的信息,并具备注意力机制来关注相关输入。逐步生成的特性使其非常适合输出可变长度序列的任务。
四、Mask解码器
Mask解码器(Masked Decoder)是自然语言处理中一个常见的算法组件,它结合了Mask机制和解码器,主要应用于具有潜在语义的序列填充任务。
Mask解码器的工作流程是:
- 对输入序列进行Mask操作,用[MASK]等特殊标记遮盖某些输入元素。
- 输入被遮盖的序列到解码器中。
- 解码器需要基于序列的上下文和其内部表示,预测每个[MASK]位置的原始语义元素。
- 损失函数结合预测结果与原序列计算交叉熵等,用于优化解码器参数。
例如,在文本摘要任务中,可遮盖原文的某些词汇,要求解码器来预测这些词汇,以学习文本的内在语义。
Mask解码器的优点是:
- 增强解码器预测语义元素的能力。
- 遮盖可控,不同比例掩码可应对不同难度任务。
- 可迁移到编码器中,组成BERT等进行预训练。
Mask解码器让解码器在解码过程中关注语义,而不仅仅是顺序预测,增强了其理解和生成能力。它现被广泛应用于文本生成、对话等自然语言处理任务中。
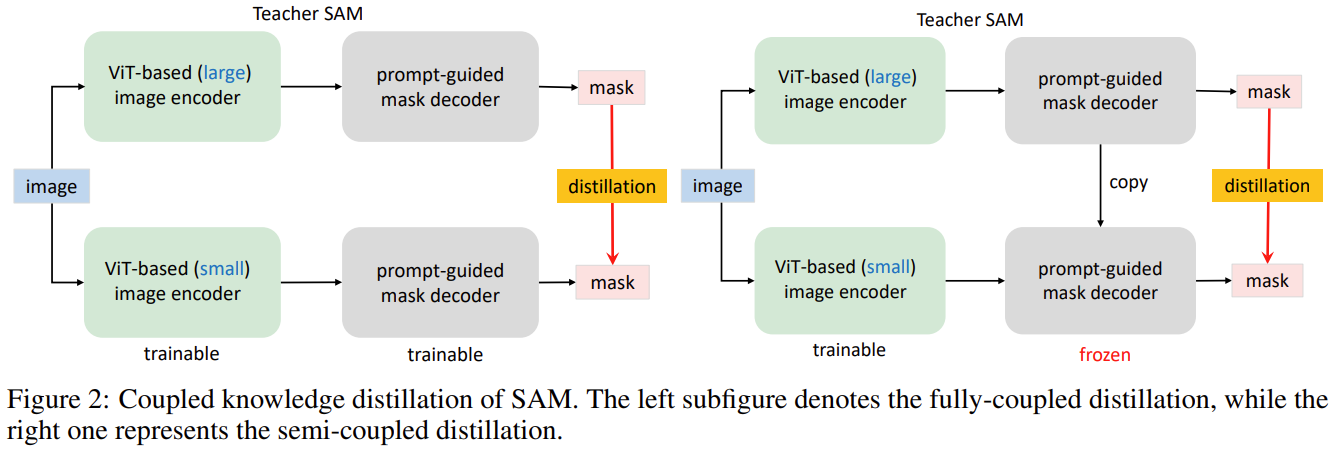
五、耦合蒸馏
耦合蒸馏(Coupled Distillation)是一种知识蒸馏技术,其核心思想是:
- 构建两个具有相同模型结构的学生模型。
- 两个学生模型一起联合训练,相互监督。
- 每个学生模型不仅从教师模型中吸收知识,也从另一个学生模型中获取额外的监督信号。
- 两个学生模型互相模仿,并作为对方的教师,实现知识的双向传递和融合。
具体做法是:
(1) 定义两个初始化参数不同的学生模型S1和S2。
(2) S1的训练目标是拟合教师模型T的输出,同时模仿S2的输出。
(3) S2的训练目标是拟合教师模型T的输出,同时模仿S1的输出。
(4) 迭代训练S1和S2,使其相互监督并不断提升对方。
这种相互耦合的蒸馏方式,可以让两个模型正确的知识得以强化,错误的知识得以纠正,从而获得更好的学习效果。
耦合蒸馏增加了模型之间的互学习机会,是一种很有效的小模型蒸馏方法。已经在各种视觉和NLP任务上取得了SOTA的结果。

六、半耦合
半耦合(Semi-coupled)通常指两个系统或组件之间,既有一定的互相关联,但又保持着一定独立性的状态。其关键要点包括:
- 两者既不完全独立,也不完全耦合。保持适当的中间状态。
- 存在定向的相互制约关系,但可以单独运行。
- 信息交流是有选择的,不是完全对等开放。
- 可以根据需要调整耦合程度,实现解耦或增强耦合。
- 既发挥协同作用,也保持相对独立的可拓展性。
- 需要控制好耦合关系,防止过于紧密或过于松散。
例如,在工程设计中,两台装置可以半耦合连接,既相互制约,又可分别工作。
在组织管理中,两个部门半耦合,既沟通协作,又有自己的职责。
总之,半耦合追求适当的平衡,将互相关联性和独立性结合起来,发挥两者的优势。它在很多复杂系统的设计中都可以发挥 important 作用。
七、图像编码器和组合解码器的耦合优化
在我看论文时,有这样一句话:
当执行从原始SAM到较小图像编码器的KD时,困难主要在于图像编码器和组合解码器的耦合优化。
- 原始模型:一个大型的自监督语音模型(SAM),包含图像编码器和解码器。
- 目标模型:一个较小的模型,其图像编码器的参数/结构较原始SAM的图像编码器小。
- 知识蒸馏目标:将原始SAM模型中提取的知识迁移到目标模型。
- 存在的困难:图像编码器和解码器之间本身存在耦合关系。在进行KD的时候,不仅要训练好小图像编码器,还需要保证解码器可以适配这个新的小编码器。
- 这就需要对图像编码器和解码器进行耦合优化,使二者可以协同工作。这增加了训练目标模型的难度和复杂度。
- 如果只优化编码器,而不考虑解码器,就可能导致最终的目标模型表现不佳。
所以这句话强调了在进行模型压缩类的KD时,需要关注各个组件的耦合关系,通过耦合优化确保知识可以有效迁移到新的模型结构中。这里的关键在于编码器和解码器的协同优化。

科技之力与好奇之心,共建有温度的智能世界
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)